Evolution Strategy - OpenAI’s Challenge to DeepMind & Reinforcement Learning
Evolution Strategy - OpenAI’s Challenge to DeepMind & Reinforcement Learning
- Last Updated: December 2, 2024
Yitaek Hwang
- Last Updated: December 2, 2024

Elon Musk must be a happy man right now. As many of you know, SpaceX successfully launched and landed a used rocket, making aerospace history and moving us closer to the age of commercial space travel. What you may have missed, however, is what OpenAI — a non-profit AI research team led by Musk — discussed at EmTech Digital conference. It's called Evolution Strategy (ES).
OpenAI’s research director, Ilya Sutskever, demonstrated that the well-known optimization technique achieves strong performance on typical Reinforcement Learning (RL) benchmarks such as beating classic Atari games. Since ES doesn’t require the backpropagation that makes RL so computationally intensive, the system is easier to scale in distributed settings. It also works well within environments that have sparse rewards and fewer hyperparameters to tune. Sutskever and the team at OpenAI believe that evolution strategy can position itself as a scalable alternative to the reinforcement learning that made DeepMind so prominent in the field.
Wait…what’s Reinforcement Learning again?
Machine learning tasks can loosely be classified into three broad categories:
- Supervised learning: determining a pattern given example inputs with output labels (e.g. SVM, decision tree, regression).
- Unsupervised learning: determining a pattern given example inputs without output labels (e.g. k-means, clustering).
- Reinforcement learning: learning in a dynamic environment based on rewards and punishments (e.g. Q-learning, AlphaGo)
Let’s take a classic game example of pong. An RL agent learns a policy function, which defines how the agent should behave given an input (i.e. how to move the paddle given the pixels of the screen). The system keeps track of the sequence of states (input pixels), actions taken, and the rewards/punishments to improve the policy. Also, to encourage the agent from taking the same path, a measure of randomness is introduced in the environment so that the agent explores various outcomes. Eventually, the agent learns an optimal policy to perform well in the environment — or in this case, play pong and beat the opponent.
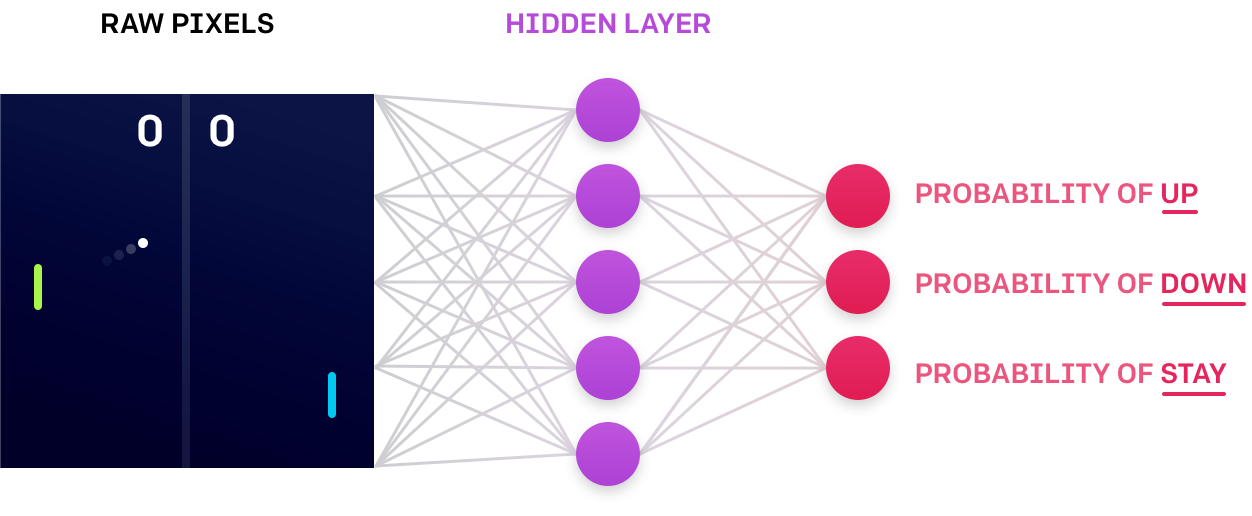
Image: OpenAI Blog
Then what is Evolution Strategy?
ES is an old idea that optimizes for the best parameters using guess and check. Forget about the agents, environment, and rewards/punishments involved with RL. Take the learning process as a black-box optimization problem where you start out with random parameters and tweak them towards ones that worked better.
For example, at each time step, we generate several parameter vectors by jittering a vector with gaussian noise. After evaluating how each of those parameters performed, we add the rewards of each policy and use the weighted sum as the updated parameter. In mathematical terms, if we generate 100 vectors, we are estimating the gradient of the expected reward using finite differences in 100 random directions. You can read more on OpenAI’s blog.
So why is Evolution Strategy better than Reinforcement Learning?
Both ES and RL optimizes the expected reward of the system. The key difference is that RL injects noise in the actions (guessing on the best action) whereas ES injects noise on the parameters (guessing on the best parameter).
This gives evolution strategy certain advantages, namely:
- ES is much faster as it requires no backpropagation, which is used in neural networks.
- ES is highly parallelizable as each agent only needs to communicate few scalar vectors, not entire parameter vectors like RL.
- ES is robust as it can explore networks that aren’t differentiable and is not affected by the exploding gradient problem in RNNs.
Due to its simplicity, evolution strategy clearly shows advantages in scalability and speed over RL. The surprising result of OpenAI’s research was that the performance of an ES system were comparable to an RL system using classic Atari games. An ES trained on 720 cores in 1 hour achieved similar performance to Deep RL Asynchronous Advantage Actor-Critic (A3C) trained on 32 cores in 1 day on Atari games:

Image Credit: OpenAI
Conclusion
ES follows the trend of repurposing old ideas to push the state of AI research forward (see AlexNet for CNN and Deep Q-Learning for RL). While evolution strategy has some limitations, OpenAI’s work shows that ES approaches can be used as an alternative approach that might reduce code complexity and time to train. The advantages of parallel computing and speed can potential help agents tackle even more complex tasks that would have crippled RL systems.
The Most Comprehensive IoT Newsletter for Enterprises
Showcasing the highest-quality content, resources, news, and insights from the world of the Internet of Things. Subscribe to remain informed and up-to-date.
New Podcast Episode

The State of Smart Buildings
Related Articles



Related Solutions

Retail Shelf Utilization Monitoring
Improve inventory management, boost revenue, optimize staff efficiency, and enhance customer experience.
Improve inventory management, boost revenue, optimize staff efficiency, and enhance customer experience.
Leverege
Leverege

Bottom of Basket for Grocery Stores
Enables grocery stores to automatically detect bottom cart items, alert cashiers and help reduce shrinkage
Enables grocery stores to automatically detect bottom cart items, alert cashiers and help reduce shrinkage
Leverege
Leverege

Service Intelligence for Auto Service Providers
Gain insights into bay utilization, crew performance, and improve customer satisfaction
Gain insights into bay utilization, crew performance, and improve customer satisfaction
Leverege
Leverege
Related Solutions
Retail
Retail Shelf Utilization Monitoring
Improve inventory management, boost revenue, optimize staff efficiency, and enhance customer experience.
Leverege
Retail
Bottom of Basket for Grocery Stores
Enables grocery stores to automatically detect bottom cart items, alert cashiers and help reduce shrinkage
Leverege
Automotive
Service Intelligence for Auto Service Providers
Gain insights into bay utilization, crew performance, and improve customer satisfaction
Leverege