Improving Data Center Reliability With IoT
Improving Data Center Reliability With IoT
- Last Updated: December 2, 2024
Ron Bartels
- Last Updated: December 2, 2024

In many technology-based systems—here we will use data centers as the primary example—reliability is correlated with availability. Availability is typically expressed in textbooks as a percentage of the agreed service time of a system less any unplanned downtime. The important thing to note here is that availability isn't just about pure uptime:
- The metric is based on a business agreement for the expected time a solution is required to be operational.
- Any planned maintenance is also excluded.
This is often how most contracts are written in the fine print. However, most data center clients disregard this textbook definition and clock the actual uptimes without any deviations.
How Is Availability Determined and Described?
The 9s Technique
Availability is often expressed using the 9s technique: a formula to describe data center uptime. The better the availability, the better the perceived maturity of the underlying infrastructure. This measurement does not translate into a direct business value unless the measured cost of downtime is used to justify risk mitigation. However, the only suitable metrics available to conduct this exercise around business value, without it being time-consuming, are industry and vertical sector benchmarks.
The typical values of the 9s technique are from two 9s to five 9s. Here's a breakdown:
- 99 percent availability: 5,256 minutes (87.6 hours) / year downtime
- 99.5 percent availability: 2,628 minutes (43.8 hours) / year downtime
- 99.9 percent availability: 528 minutes (8.8 hours) / year downtime
- 99.99 percent availability: 53 minutes / year downtime
- 99.999 percent availability: 5 minutes / year downtime
The above values are mapped to the following terms by Gartner:
- Normal business availability is 99.5 percent or less
- High availability is 99.9 percent
- Fault resilient is 99.99 percent
- Fault tolerant is 99.999 percent
- Continuous processing is as close to 100 percent as possible
The only way that continuous processing in a data center can be achieved is if regular and consistent maintenance is conducted. To take a system down once a month for a day will impact 3.3 percent of the overall availability if the business requirement is for continuous processing.
Improvement Amidst Complexity
Just like a car, it's impossible to run an infrastructure without regular maintenance. This regular maintenance also includes hardware and software refreshes. High reliability cannot be achieved using singular systems, and, as a minimum, two parallel systems need to be deployed where one continues to provide services while the other is being maintained.
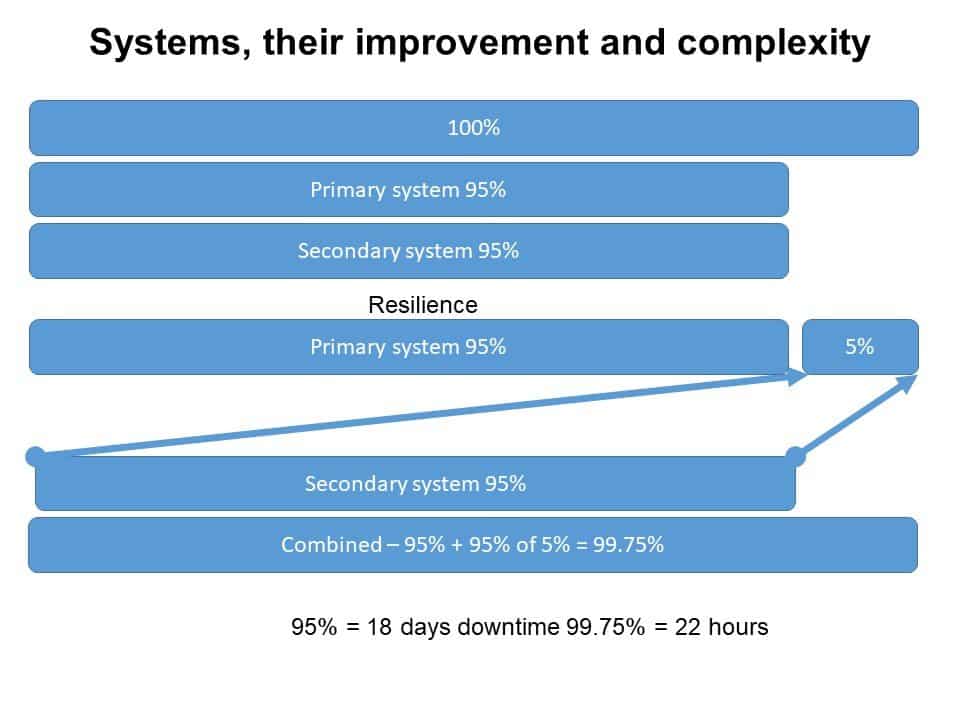
Image Credit: Ron Bartels
The above diagram represents the complexity associated with improving reliability by using duplicated systems and how the availability percentage increases in value. As components are duplicated, the probability of failure is reduced and availability improves.
At a fundamental level, the business is only interested in providing services that will meet the vision of what they are doing, be it flipping burgers or manufacturing widgets. Any outage that has a negative consequence on this vision is what will be assumed as downtime. Importantly, this is not limited to tin in a specific data center but is inclusive of all related resources be they people, processes or technology!
Reliability and availability are essential to many business systems. Data Centers are an example of how IoT devices can enable better tracking and data collection to improve stability and quickly identify issues.
Data Center Infrastructure
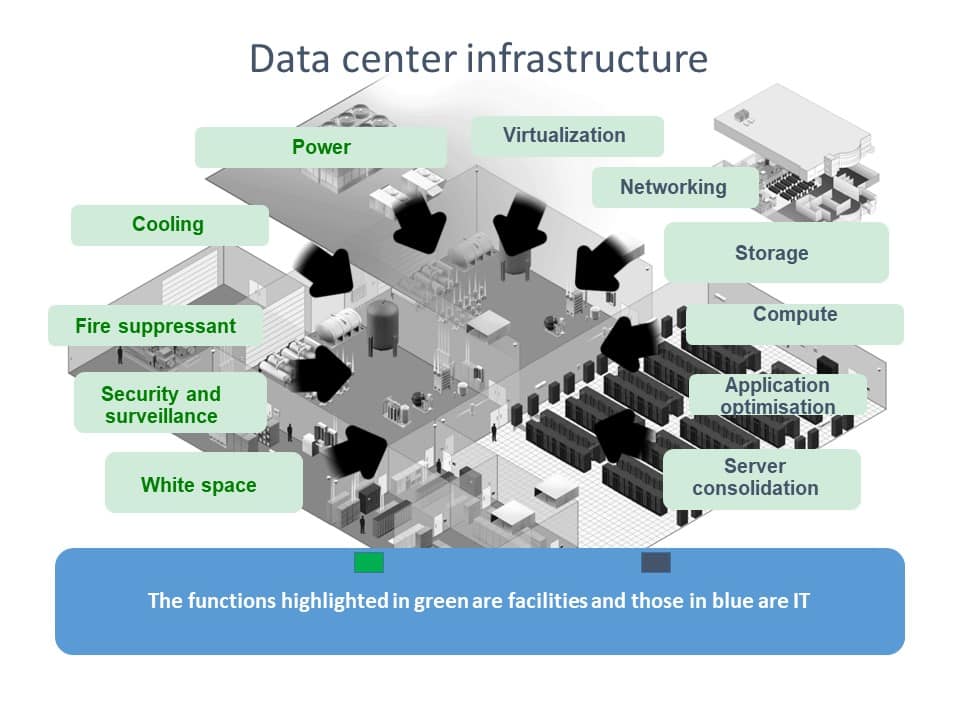
Image Credit: Ron Bartels
The above diagram represents the tin in the data center which includes both the facilities and IT infrastructure. There are multiple components, and, to achieve reliability, each of these components needs to be individually duplicated. In a data center, these are significant investments that are required. In the power infrastructure function, for example, multiple standby generators would be required. Even though this is complex, it's not the silver bullet to reliability. As mentioned previously, it's not only about the technology and those associated components, it's an extended eco-system.
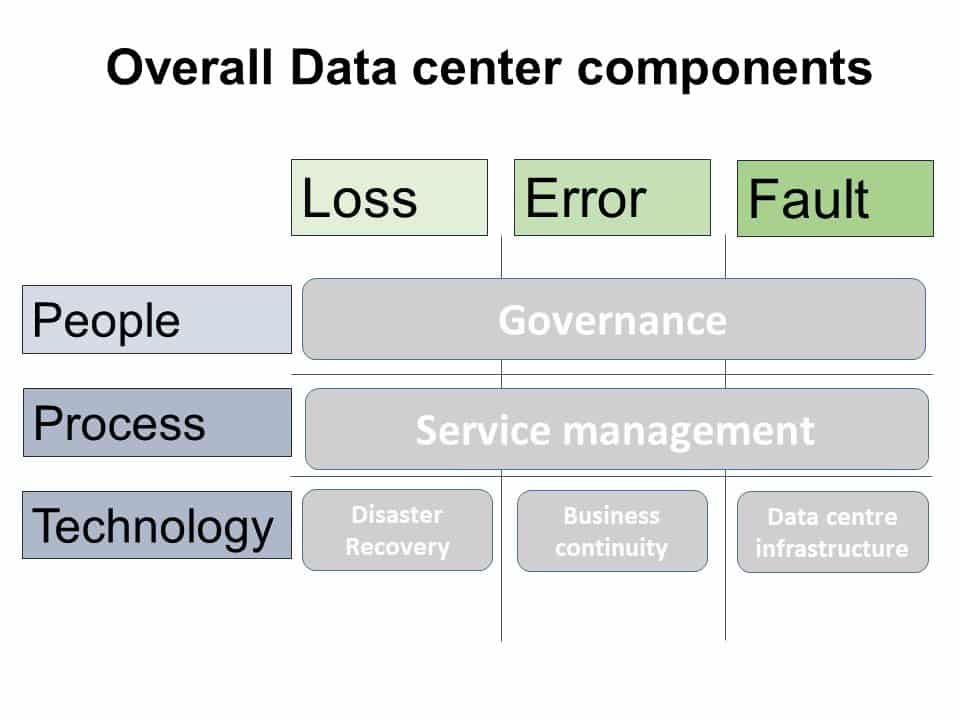
Image Credit: Ron Bartels
This eco-system technology is about the reliability within the infrastructure and includes catering for the functions of addressing business continuity and disaster recovery. Furthermore, process reliability needs to be addressed by service management, and people reliability needs to be addressed by governance. The impact of this is that reliability with the data center is a stack of all these components.
The Data Center Reliability Stack
The diagram below represents a simplified view of the data center reliability stack. The business using services can be impacted by any failure event in the whole stack chain, not just the technology component. The impact of failures in the other components is quite similar in outcome to a failure of technology.
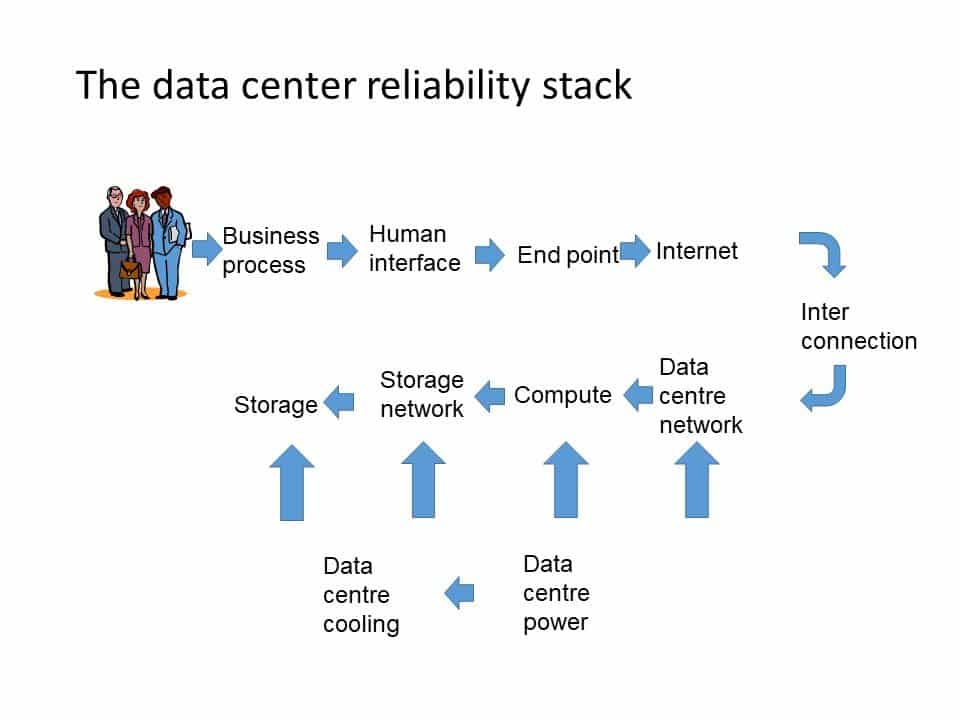
Image Credit: Ron Bartels
Unlike technology components which can be duplicated to improve reliability, this strategy does not work with processes or people. These components need to be matured using training and simulation which improve their reliability. This is further supplemented by Deming-type methodologies of continuous improvement.
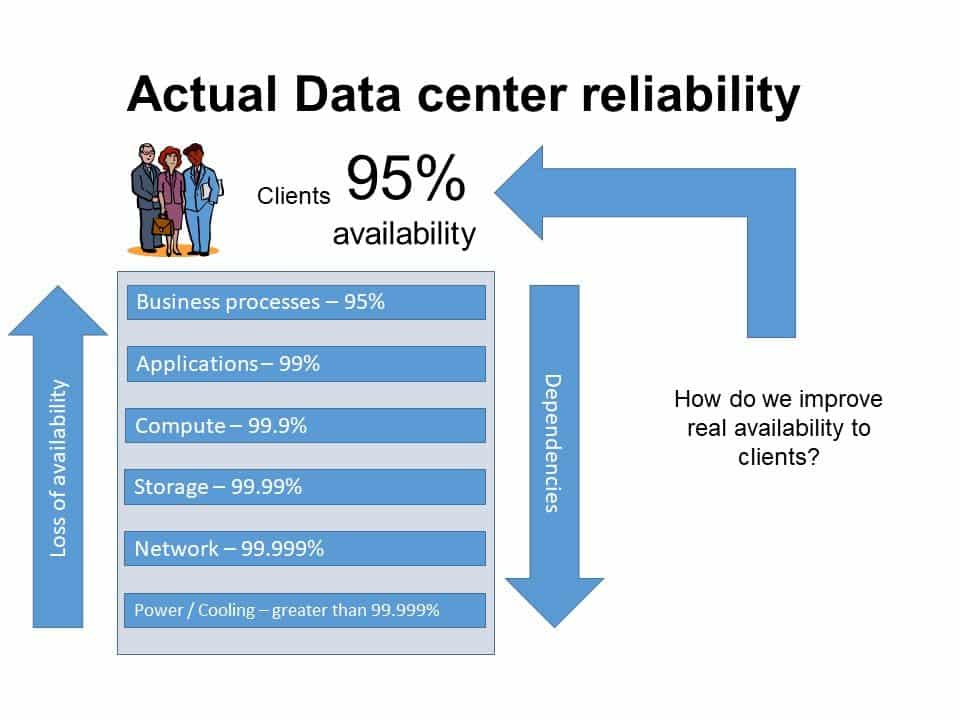
Image Credit: Ron Bartels
The impact of the reliability stack is that the underlying data center facilities availability (even though it might be five 9s) doesn't translate to value from the perception of clients. The above diagram clarifies the understanding of the actual data center reliability stack as reliability decreases in value as you progress further up the stack!
Why IoT Should Be Included in the Data Center Reliability Stack
The Internet of Things (IoT) now needs to plug into this stack. It's more than just enabling online connectivity and visibility to Environmental Monitoring Systems (EMS) or Building Management Systems (BMS) into the data center facilities components.
There's a further requirement to provide the same and universal visibility to the telemetry provided by the data center IT infrastructure. Traditionally, these have been separate silos, so combining them into a single pane of glass to determine infrastructure reliability is challenging but not insurmountable. This is where the first wave of IoT enabled sensors, devices and platforms are being deployed.
The greater challenge faced by IoT platforms is to augment this first wave with workflows that measure and track process metrics. This includes the governance of the people component. The integration of this is possible with wearables which can assist in providing a data center black box type ability like the one commonly used and found in aviation. IoT becomes the basis on which decisions around training and process improvement are achieved with the black boxes being the data sources. In aviation, process improvement is often implemented by updating cockpit checklists, and data centers are no different.
The use of documentation repositories that include checklists to ensure reliability is then used by data center personnel in a similar fashion to how a pilot would manage a complex aircraft. Aircraft and data centers are similar entities as both use technology duplication to improve reliability. Thus, it'll be no surprise that similarities exist in the development of both environments. In aviation, a major incident might be attributed to pilot error, and data centers are not immune to similar types of problems. The pilot in the data center is a data center engineer.
Toward Resilient Availability
The widespread introduction of IoT into data centers will allow for actual business value to be determined directly instead of relying on industry benchmarks. As an added benefit, data centers that are more resilient through IoT solutions will also feed value back into IoT, because most IoT solutions rely upon cloud infrastructure.
The Most Comprehensive IoT Newsletter for Enterprises
Showcasing the highest-quality content, resources, news, and insights from the world of the Internet of Things. Subscribe to remain informed and up-to-date.
New Podcast Episode

The State of Smart Buildings
Related Articles



Related Solutions

Monitoring and Asset Control for Industrial Environments
A comprehensive, secure IIoT platform for real-time monitoring, predictive maintenance, and remote asset control.
A comprehensive, secure IIoT platform for real-time monitoring, predictive maintenance, and remote asset control.
WIKA
WIKA

Remote Monitoring and Diagnostics for Vehicles
Remotely monitor vehicle location and on-board diagnostic data with the Golioth IoT OBD-II / CAN asset tracker and instant IoT cloud.
Remotely monitor vehicle location and on-board diagnostic data with the Golioth IoT OBD-II / CAN asset tracker and instant IoT cloud.
Golioth
Golioth

Connected Health Telemetry Management
Quickly launch and cost-effectively scale the delivery and management of connected health solutions with reliable, secure, and scalable connectivity.
Quickly launch and cost-effectively scale the delivery and management of connected health solutions with reliable, secure, and scalable connectivity.
KORE
KORE
Related Solutions
Industrial
Monitoring and Asset Control for Industrial Environments
A comprehensive, secure IIoT platform for real-time monitoring, predictive maintenance, and remote asset control.
WIKA
Supply Chain & Logistics
Remote Monitoring and Diagnostics for Vehicles
Remotely monitor vehicle location and on-board diagnostic data with the Golioth IoT OBD-II / CAN asset tracker and instant IoT cloud.
Golioth
Healthcare
Connected Health Telemetry Management
Quickly launch and cost-effectively scale the delivery and management of connected health solutions with reliable, secure, and scalable connectivity.
KORE