The Leading Causes of Dirty Data
The Leading Causes of Dirty Data
- Last Updated: December 2, 2024
CloudFactory
- Last Updated: December 2, 2024

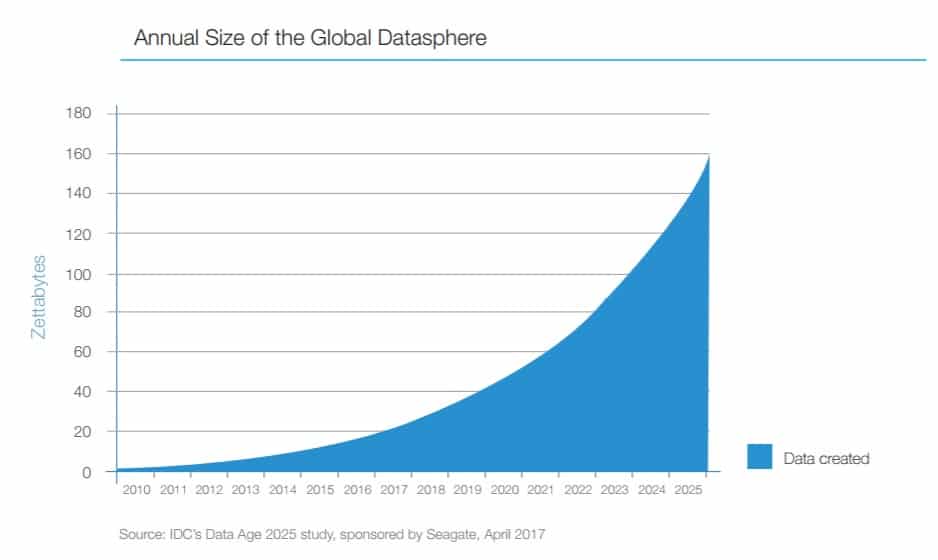
The world is producing data at exponential rates. By 2025, the global datasphere will include 10 times the amount of data generated last year alone, according to IDC’s Data Age 2025. All of this data generation compounds an already common problem: “dirty data.”
Businesses across every industry are pondering how they can use data to better serve customers, create products, and disrupt industries. Yet fewer than half (44%) trust their data to make important business decisions, according to Experian’s 2017 Global Data Management Benchmark Report. C-level executives are the biggest skeptics, believing 33% of their organizations’ data is inaccurate.
The first step to cleaning up dirty data is to understand how it got dirty in the first place. Let’s take a look at some of the leading causes of dirty data.
Human Error
The biggest challenge in maintaining data accuracy is human error, according to the Experian report. Dirty data caused by human error can take multiple forms:- Incorrect - The value entered does not comply with the field's valid values. For example, the value entered for month is likely to be a number from 1 to 12. This value can be enforced with lookup tables or edit checks.
- Inaccurate - The value entered is not accurate. Sometimes, the system can evaluate the data value for accuracy based on context. For most systems, accuracy validation requires a manual process.
- In violation of business rules - The value is not valid or allowed, based on the business rules (e.g., An effective date must always come before an expiration date.)
- Inconsistent - The value in one field is inconsistent with the value in a field that should have the same data. Particularly common with customer data, one source of data inconsistencies is manual or unchecked data redundancy.
- Incomplete - The data has missing values. No data value is stored in a field. For example, the street address is missing in a customer record.
- Duplicate - The data appears more than once in a system of record. Common causes include repeat submissions, improper data joining or blending, and user error.
Quality Issues in IoT
Systems that use the Internet of Things (IoT) connect devices and sensors to software that can interpret the data and make it visible to decision makers and useful for business. Data is the lifeblood of those systems, and as we discussed in part one, dirty data can be costly.James Branigan, IoT software platform developer and founder of Bright Wolf, works with businesses to start, save, or reboot IoT initiatives. Based on his experiences, he explains in detail four factors that produce high-quality data in a series of articles, “Four Critical Design Factors for IoT Project Success.” According to Branigan, IoT failures are most often caused by issues in one or more of these areas:
- Trust is the foundation of an IoT system. It means that you know you are talking to the right device and the device knows it is talking to the correct end system.
- Identity refers to the association of incoming data with the correct time series history and addressing messages to the correct device.
- Time is an accurate date and time stamp for each event and data point. In IoT, it can be a challenge for devices operating across time zones and where users can make manual adjustments to clocks, for example.
- Chain of custody refers to understanding the complete history of each data point, including details about the devices and software that processed the data.
The Bottom Line
For decades, the information technology world has used the term “garbage in, garbage out.” It means no matter how accurate a system’s logic is, its results will be incorrect if the input it has received is not valid. Perhaps never before has the phrase meant so much as it does today, when identifying patterns in reliable data can help business leaders transform entire services, products, and industries.To achieve those outcomes, data must be clean, and structured. The next and final article in this series will explore some of the steps you can take to tackle your organization’s dirty-data problem.
Written by Nanette George, Senior Marketing Manager at CloudFactory.
The Most Comprehensive IoT Newsletter for Enterprises
Showcasing the highest-quality content, resources, news, and insights from the world of the Internet of Things. Subscribe to remain informed and up-to-date.
New Podcast Episode

How Drones and Telecom Enable Aerial IoT
Related Articles



Related Solutions

Monitoring and Asset Control for Industrial Environments
A comprehensive, secure IIoT platform for real-time monitoring, predictive maintenance, and remote asset control.
A comprehensive, secure IIoT platform for real-time monitoring, predictive maintenance, and remote asset control.
WIKA
WIKA

Remote Monitoring and Diagnostics for Vehicles
Remotely monitor vehicle location and on-board diagnostic data with the Golioth IoT OBD-II / CAN asset tracker and instant IoT cloud.
Remotely monitor vehicle location and on-board diagnostic data with the Golioth IoT OBD-II / CAN asset tracker and instant IoT cloud.
Golioth
Golioth

Connected Health Telemetry Management
Quickly launch and cost-effectively scale the delivery and management of connected health solutions with reliable, secure, and scalable connectivity.
Quickly launch and cost-effectively scale the delivery and management of connected health solutions with reliable, secure, and scalable connectivity.
KORE
KORE
Related Solutions
Industrial
Monitoring and Asset Control for Industrial Environments
A comprehensive, secure IIoT platform for real-time monitoring, predictive maintenance, and remote asset control.
WIKA
Supply Chain & Logistics
Remote Monitoring and Diagnostics for Vehicles
Remotely monitor vehicle location and on-board diagnostic data with the Golioth IoT OBD-II / CAN asset tracker and instant IoT cloud.
Golioth
Healthcare
Connected Health Telemetry Management
Quickly launch and cost-effectively scale the delivery and management of connected health solutions with reliable, secure, and scalable connectivity.
KORE