Machine Learning Application: Predicting Parking Difficulty
Machine Learning Application: Predicting Parking Difficulty
- Last Updated: December 2, 2024
Yitaek Hwang
- Last Updated: December 2, 2024

According to the Telegraph, an average driver wastes a total of 2,549 hours looking for parking. That’s 106 days of wasted time. Now, those are statistics in the UK, but I bet that drivers in the US living in metro areas waste just as much — if not more — time looking for parking.
Last week, Google quietly launched a new parking feature for Google Maps on Android across 25 major US cities. If you are in these metro areas, you will now see a red parking sign that indicates limited parking availability to help you plan your trip.
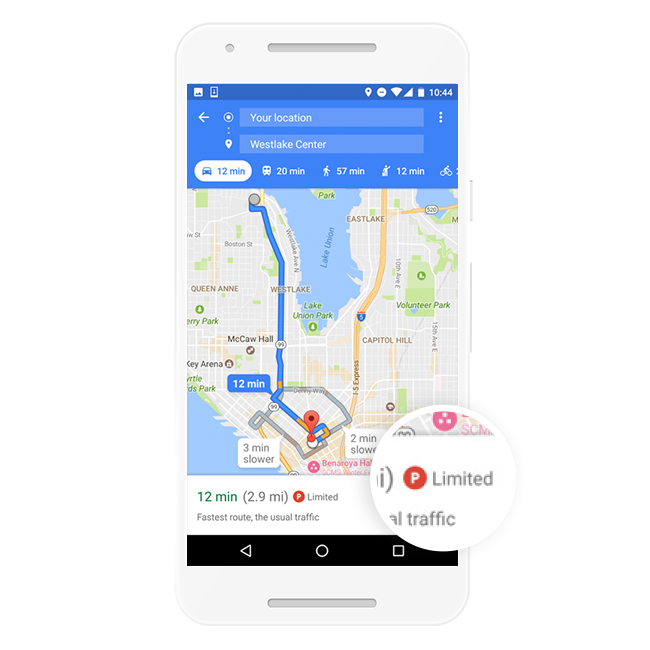
The interesting part of this update is that it does not rely on internet-connected parking meters; which often provide incomplete or wrong information due to illegal parkers or those who depart early from their spot. Instead, Google Maps combined crowdsourced data and relatively simple machine learning algorithms to classify parking difficulty.
Google also noted that in a pre-launch experiment, they saw a “significant increase in clicks on the transit travel mode button, indicating that users with additional knowledge of parking difficulty were more likely to consider public transit rather than driving.” Just by indicating parking difficulty, cities can encourage people to take public transit rather than drive, perhaps mitigating traffic problems.
Machine Learning Application
To train its algorithm, Google set out to classify how “hard” or “easy” it was to find parking by measuring the time it took for its users to park the car. After correlating this information with location data, Google had to then filter out false positives: users parking in a private lot or users arriving via taxi, fooling the system into thinking that parking space was easily available.
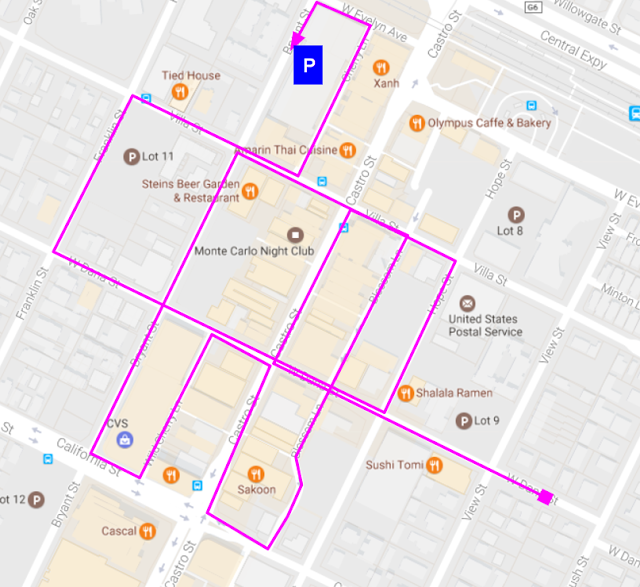
Image Credit: Techcrunch
To solve this issue, Google determined that if users circled around a location like in the picture above, it usually suggested that parking might be difficult. To recognize this behavior, they took the difference between when they should have arrived at the location versus when they actually arrived there, with a large difference indicating more difficulty in finding a parking spot. Google also added other features such as variability based on time of day, date, and historical parking data to tune the model.
Google used a simple logistic regression model to train its algorithm. They reasoned that logistic regression fits well for this example since:
- The algorithm is well-understood and resilient to noise.
- Interpretation of the model is straightforward (probability of parking difficulty can be mapped to “easy” or “limited parking”).
- Verifying the influence of each feature is relatively simple. Surprisingly, dispersion of parking locations turned out to be the most important predictors of parking difficulty, more so than the difference in expected vs. actual time of arrival.
Google’s new parking difficulty predictor gives us two lessons regarding smart cities:
First, not all smart city applications require sensors. Sometimes the data is already available, and we don’t have to resort to adding new sensors to gather that information.
Second, even though neural networks are popular and accurate, sometimes simpler algorithms can fit the need just as well.
The Most Comprehensive IoT Newsletter for Enterprises
Showcasing the highest-quality content, resources, news, and insights from the world of the Internet of Things. Subscribe to remain informed and up-to-date.
New Podcast Episode

How Drones and Telecom Enable Aerial IoT
Related Articles



Related Solutions

5G Connectivity for Public Transit
Enhance efficiency, safety, security, and passenger experience with future-proof 5G connectivity.
Enhance efficiency, safety, security, and passenger experience with future-proof 5G connectivity.
Digi
Digi
Seed Container Tracking
GPS location, environmental sensing, and BLE capabilities to monitor seed container movement and condition.
GPS location, environmental sensing, and BLE capabilities to monitor seed container movement and condition.
SODAQ
SODAQ
GPS Tracking for Law Enforcement
Monitor assets, vehicles, and suspects with precision and reliability using the Bolt 4G device and an intuitive platform.
Monitor assets, vehicles, and suspects with precision and reliability using the Bolt 4G device and an intuitive platform.
Datablaze
Datablaze
Related Solutions
Smart Cities
5G Connectivity for Public Transit
Enhance efficiency, safety, security, and passenger experience with future-proof 5G connectivity.
Digi
Agriculture
Seed Container Tracking
GPS location, environmental sensing, and BLE capabilities to monitor seed container movement and condition.
SODAQ
Smart Cities
GPS Tracking for Law Enforcement
Monitor assets, vehicles, and suspects with precision and reliability using the Bolt 4G device and an intuitive platform.
Datablaze