Mobile is Eating the World, Adaptive Attention via a Visual Sentinel, and Google’s Great AI Awakening
Mobile is Eating the World, Adaptive Attention via a Visual Sentinel, and Google’s Great AI Awakening
- Last Updated: December 2, 2024
Yitaek Hwang
- Last Updated: December 2, 2024

Mobile is Eating the World
The following presentation is from Benedict Evans of Andreessen Horowitz via his website: “Mobile is Eating the World”
Summary:
- Mobile S-Curve is moving from creation to deployment and is passing the PC S-curve with Google, Apple, Facebook, and Amazon (GAFA) now having 3x the scale of Microsoft and Intel (Wintel).
- The ubiquity of mobile means that GAFA is now building on an ecosystem that commoditizes almost everything before: custom hardware, retail, content, cars, etc.
- Deep learning and big data have enabled the AI-transformation: AI affects both the top and bottom of the technology stack (e.g. Google’s TPUs to GAFA’s machine learning cloud APIs).
- If apps have won mobile and changed computing in the early part of this decade, Evans sees a new generation of computing coming with AI-driven services. He calls them “frictionless computing” where hardware sensors come as unbundled apps: think of the Amazon Echo and Snapchat’s Spectacles.
- The important ramification of frictionless computing is that removing that friction also removes choices for customers. Evans sees this affecting eCommerce and the retail sector in the same way that the Internet changed media.
- Autonomous cars seem to follow the path of unbundling phones. In 2001, Nokia owned most of its manufacturing and deemed it a strength. In 2016, Apple owns none of its 189 suppliers. The competitive moat in cars remain unclear, but we know that autonomous cars will change not just the oil production industry, but parking, real estate, and insurance.
Takeaway:
Much has been written and talked about how autonomous cars will transform the future. But changes in eCommerce and retail seem more immediate and certain. The use of data in the 1990s shaped better supply chain and logistics. The 2000s was marked by data-driven advertising. Now with machine learning, scaling curation will be possible. Also with frictionless computing, like Amazon’s dash button, many intermediaries will be cut out and fresh purchasing journeys will influence new kinds of purchasing decisions.
Adaptive Attention via a Visual Sentinel
The intersection of computer vision and natural language processing has brought us the technology to automatically tag and generate captions for images. This technology can not only help visually impaired users (see OrCam or Aipoly), but also help sort through unstructured images (Google, Facebook photo search). One of the papers from NIPS 2016 that garnered much attention is from Salesforce Research — Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning. Here we see efforts to take advantage of our understanding of language for better captioning rather than just sticking a RNN to CNN to merge the two networks.
*** For other highlights, check out Andreas Stuhlmüller’s “50 things I learned at NIPS 2016”
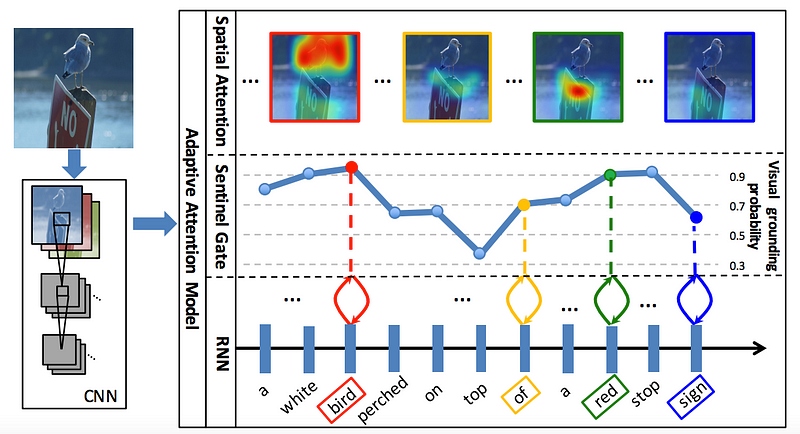
Summary:
- Previous works typically use an attention mechanism that produces a spatial map of image regions linked to each generated word. This means that attention models attend to each image at every time step, regardless of its importance for visual signals.
- The image above generates a caption “A white bird perched on top of a red stop sign.” The words like “a” and “of” do not provide canonical visual signals, and language correlations take care of relational descriptors like “on” and “top.” Not only are resources wasted in attending to every word, but training with non-visual words can lead to worse performance in generating captions.
- The authors of this research utilize a LSTM extension to create an additional visual sentinel vector on top of its hidden layer. This essentially creates an adaptive attention encoder-decoder framework that switches from visual signals to language models when necessary.
- Concretely, the model attends to the image more for visual words like “white”, “bird”, and “stop,” while using the visual sentinel to generate captions for “top”, “of”, and “on.”
Takeaway:
The authors show that the model successfully “learns” when to attend to the image or the visual sentinel. The model tested on the COCO image captioning dataset and Flickr30K show significant improvements to the existing models. Salesforce Research team’s success is encouraging as more work will be done in interdisciplinary research problems both in academia and in industry.
Quote of the Week
The most important thing happening in Silicon Valley right now is not disruption. Rather, it’s institution-building — and the consolidation of power — on a scale and at a pace that are both probably unprecedented in human history. Google Brain has interns; it has residents; it has “ninja” classes to train people in other departments.
But even enormous institutions like Google will be subject to this wave of automation; once machines can learn from human speech, even the comfortable job of the programmer is threatened…The kinds of jobs taken by automatons will no longer be just repetitive tasks that were once — unfairly, it ought to be emphasized — associated with the supposed lower intelligence of the uneducated classes. We’re not only talking about three and a half million truck drivers who may soon lack careers. We’re talking about inventory managers, economists, financial advisers, real estate agents. What Brain did over nine months is just one example of how quickly a small group at a large company can automate a task nobody ever would have associated with machines.

“The Great A.I. Awakening” by Gideon Lewis-Kraus on the NYT has been featured by all sorts of A.I. and data science blogs this week. The article creates a fascinating narrative about how Google’s CEO, Sundar Pinchai, turned Google from a mobile-first to an A.I.-first company, through the development of Google Translate. It is a long read, but Lewis-Kraus does an excellent job laying down the history of neural networks from Google Brain’s perspective. If you are interested in how Jeff Dean, Andrew Ng, Geoffrey Hinton, and Quoc Le came to apply deep learning onto translation tasks, give it a full read.
But the most interesting part of the article doesn’t come until the epilogue: Machines Without Ghosts. Here Lewis-Kraus introduces Berkeley philosopher John Searle’s thought that “there is something special about human ‘insight,’ [that] you can draw a clear line that separates the human from the automated.” Famous linguist and cognitive scientist, Noam Chomsky, also belittled the advances in A.I., saying that “the whole enterprise [is a] mere statistical prediction, a glorified weather forecast, [unable to] reveal [something] profound about the underlying nature of language.”
Then, Lewis-Kraus asks an acute question for us all. Even if a machine can’t tell us whether a “pronoun took the dative or the accusative case,” it is already detecting tumors in medical scans better than human radiologists, scanning through legal documents faster than credentialed lawyers, and automating almost every task you can imagine. Skeptics might point to the fact that machines trained to do complex pattern matching, cannot reason or perform logical analysis like humans. But do humans really have logical reasoning? Radiologists don’t really tell you what caused the cancer either; they’re just telling you it’s there based on patterns they’ve seen in the past. How is that fundamentally different than what machines are doing now?
The social implication of all this is that all jobs — not just the blue-collar jobs associated with repetitive tasks — can be easily replaced. No, this isn’t a Luddite’s alarmist view; it’s what Google taught us is possible. Last week’s discussion on Amazon Go by Hannah White sparked a good conversation. Whether you like it or not, it’s a conversation we will be having for years to come.
The Rundown
- 30 Day Vanilla JS Coding Challenge — Javascript30
- Learn Python Efficiently — Simply Django
- Making an MSX font — La Nueva Escuela
- How to train a GAN — GitHub
- OpenDoor: A Startup Worth Emulating — Stratechery
Resources
- Embedding Projector: visualize high dimensional data
- Learning to Learn: Learning an optimization algorithm using gradient descent
- Chess Surprise Analysis: GitHub repo on finding surprising moves in a chess game
- Universe: OpenAI’s software platform for training AI agents in game environment
- Numpy Exercises: Jupyter notebooks to practice all the numpy functions
The Most Comprehensive IoT Newsletter for Enterprises
Showcasing the highest-quality content, resources, news, and insights from the world of the Internet of Things. Subscribe to remain informed and up-to-date.
New Podcast Episode

IoT Is Finally Delivering
Related Articles



Related Solutions

Smart License Plate Recognition
Automate parking enforcement and access control with real-time vehicle identification to improves revenue collection.
Automate parking enforcement and access control with real-time vehicle identification to improves revenue collection.
Conure
Conure

Retail Shelf Utilization Monitoring
Improve inventory management, boost revenue, optimize staff efficiency, and enhance customer experience.
Improve inventory management, boost revenue, optimize staff efficiency, and enhance customer experience.
Leverege
Leverege

Bottom of Basket for Grocery Stores
Enables grocery stores to automatically detect bottom cart items, alert cashiers and help reduce shrinkage
Enables grocery stores to automatically detect bottom cart items, alert cashiers and help reduce shrinkage
Leverege
Leverege
Related Solutions
Smart Cities
Smart License Plate Recognition
Automate parking enforcement and access control with real-time vehicle identification to improves revenue collection.
Conure
Retail
Retail Shelf Utilization Monitoring
Improve inventory management, boost revenue, optimize staff efficiency, and enhance customer experience.
Leverege
Retail
Bottom of Basket for Grocery Stores
Enables grocery stores to automatically detect bottom cart items, alert cashiers and help reduce shrinkage
Leverege