Human-Centered Design for Machine Learning
Human-Centered Design for Machine Learning
- Last Updated: December 2, 2024
Guest Writer
- Last Updated: December 2, 2024

Machine learning (ML) is the science of helping computers discover patterns and relationships in data instead of being manually programmed. It’s a powerful tool for creating personalized and dynamic experiences, and it’s already driving everything from Netflix recommendations to autonomous cars.
But as more and more experiences are built with ML, it’s clear that UXers still have a lot to learn about how to make users feel in control of the technology, and not the other way round.
As was the case with the mobile revolution, and the web before that, ML will cause us to rethink, restructure, displace, and consider new possibilities for virtually every experience we build. In the Google UX community, we’ve started an effort called “human-centered machine learning” (HCML) to help focus and guide that conversation. Using this lens, we look across products to see how ML can stay grounded in human needs while solving them in unique ways only possible through ML.
Our team at Google works with UXers across the company to bring them up to speed on core ML concepts, understand how to integrate ML into the UX utility belt, and ensure ML and AI are built in inclusive ways.
If you’ve just started working with ML, you may be feeling a little overwhelmed by the complexity of the space and the sheer breadth of opportunity for innovation. Slow down, give yourself time to get acclimated, and don’t panic. You don’t need to reinvent yourself in order to be valuable to your team.
We’ve developed seven points to help designers navigate the new terrain of designing ML-driven products. Born out of our work with UX and AI teams at Google (and a healthy dose of trial and error), these points will help you put the user first, iterate quickly, and understand the unique opportunities ML creates.
Let’s get started.
1. Don’t expect Machine learning to figure out what problems to solve
Machine learning and artificial intelligence have a lot of hype around them right now. Many companies and product teams are jumping right into product strategies that start with ML as a solution and skip over focusing on a meaningful problem to solve.
That’s fine for pure exploration or seeing what a technology can do, and often inspires new product thinking. However, if you aren’t aligned with a human need, you’re just going to build a very powerful system to address a very small — or perhaps nonexistent — problem.
So our first point is that you still need to do all that hard work you’ve always done to find human needs. This is all the ethnography, contextual inquiries, interviews, deep hanging out, surveys, reading customer support tickets, logs analysis, and getting proximate to people to figure out if you’re solving a problem or addressing an unstated need people have. Machine learning won’t figure out what problems to solve. We still need to define that. As UXers, we already have the tools to guide our teams, regardless of the dominant technology paradigm.
2. Ask yourself if ML will address the problem in a unique way
Once you’ve identified the need or needs you want to address, you’ll want to assess whether ML can solve these needs in unique ways. There are plenty of legitimate problems that don’t require ML solutions.
A challenge at this point in product development is determining which experiences require ML, which are meaningfully enhanced by ML, and which do not benefit from ML or are even degraded by it. Plenty of products can feel “smart” or “personal” without ML. Don’t get pulled into thinking those are only possible with ML.
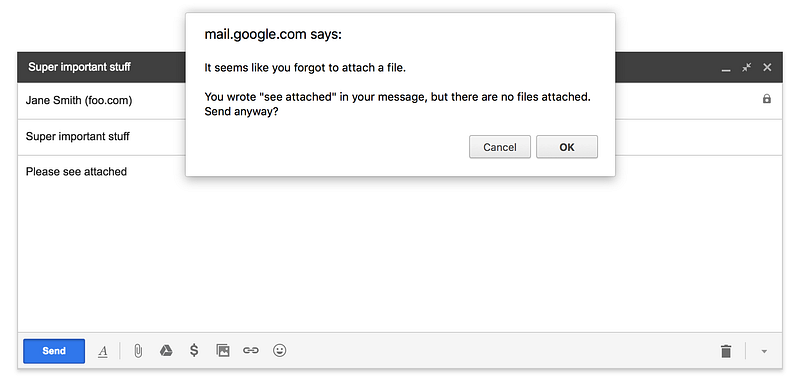
Gmail looks for phrases including words like “attachment” and “attached” to pop a reminder when you may have forgotten an attachment. Heuristics work great here. An ML system would most likely catch more potential mistakes but would be far more costly to build. Image Credit: Gmail (Google)
We’ve created a set of exercises to help teams understand the value of ML to their Applications. These exercises do so by digging into the details of what mental models and expectations people might bring when interacting with an ML system as well as what data would be needed for that system.
Here are three example exercises we have teams walk through and answer about the Applications they are trying to address with ML:
- Describe the way a theoretical human “expert” might perform the task today.
- If your human expert were to perform this task, how would you respond to them so they improved for the next time? Do this for all four phases of the confusion matrix.
- If a human were to perform this task, what assumptions would the user want them to make?
Spending just a few minutes answering each of these questions reveals the automatic assumptions people will bring to an ML-powered product. They are equally good as prompts for a product team discussion or as stimuli in user research. We’ll also touch on these a bit later when we get into the process of defining labels and training models.
After these exercises and some additional sketching and storyboarding of specific products and features, we then plot out all of the team’s product ideas in a handy 2×2:

Plot ideas in this 2×2. Have the team vote on which ideas would have the biggest user impact and which would be most enhanced by an ML solution. Image Credit: Akiko Okazaki
This allows us to separate impactful ideas from less impactful ones as well as see which ideas depend on ML vs. those that don’t or might only benefit slightly from it. You should already be partnering with Engineering in these conversations, but if you aren’t, this is a great time to pull them in to weigh-in on the ML realities of these ideas. Whatever has the greatest user impact and is uniquely enabled by ML (in the top right corner of the above matrix) is what you’ll want to focus on first.
3. Fake it with personal examples and wizards
A big challenge with ML systems is prototyping. If the whole value of your product is that it uses unique user data to tailor an experience to her, you can’t just prototype that up real quick and have it feel anywhere near authentic. Also, if you wait to have a fully built ML system in place to test the design, it will likely be too late to change it in any meaningful way after testing. However, there are two user research approaches that can help: using personal examples from participants and Wizard of Oz studies.
When doing user research with early mockups, have participants bring in some of their own data — e.g. personal photos, their own contact lists, music or movie recommendations they’ve received — to the sessions. Remember, you’ll need to make sure you fully inform participants about how this data will be used during testing and when it will be deleted. This can even be a kind of fun “homework” for participants before the session (people like to talk about their favorite movies after all).
With these examples, you can then simulate right and wrong responses from the system. For example, you can simulate the system returning the wrong movie recommendation to the user to see how she reacts and what assumptions she makes about why the system returned that result. This helps you assess the cost and benefits of these possibilities with much more validity than using dummy examples or conceptual descriptions.
The second approach that works quite well for testing not-yet-built ML products is conducting Wizard of Oz studies. All the rage at one time, Wizard of Oz studies fell from prominence as a user research method over the past 20 years or so. Well, they’re back.
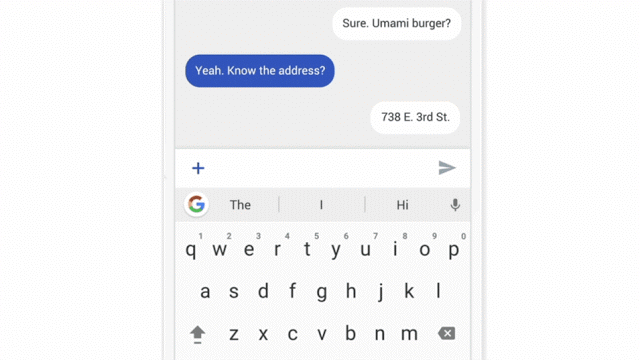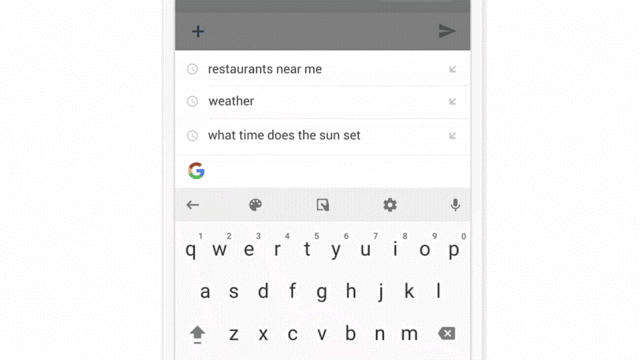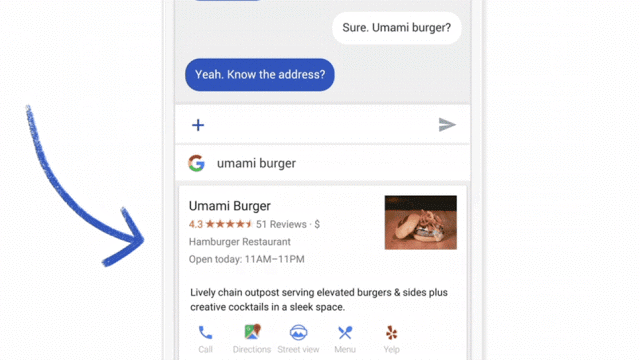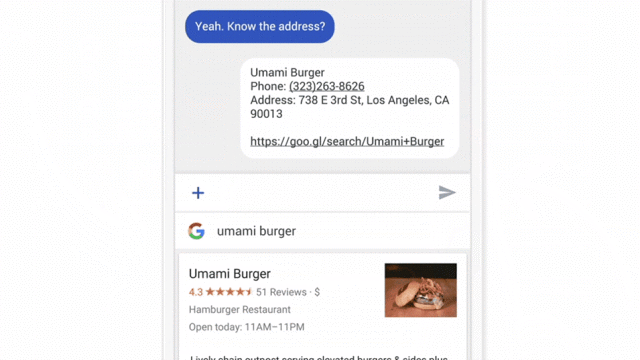
Chat interfaces are one of the easiest experiences to test with a Wizard of Oz approach. Simply have a team mate ready on the other side of the chat to enter “answers” from the “AI.” (image courtesy)
Quick reminder: Wizard of Oz studies have participants interact with what they believe to be an autonomous system, but which is actually being controlled by a human (usually a teammate).
Having a teammate imitate an ML system’s actions like chat responses, suggesting people the participant should call, or movies suggestions can simulate interacting with an “intelligent” system. These interactions are essential to guiding the design because when participants can earnestly engage with what they perceive to be an AI, they will naturally tend to form a mental model of the system and adjust their behavior according to those models. Observing their adaptations and second-order interactions with the system are hugely valuable to informing its design.
4. Weigh the costs of false positives and false negatives
Your ML system will make mistakes. It’s important to understand what these errors look like and how they might affect the user’s experience of the product. In one of the questions in point 2 we mentioned something called the confusion matrix. This is a key concept in ML and describes what it looks like when an ML system gets it right and gets it wrong.
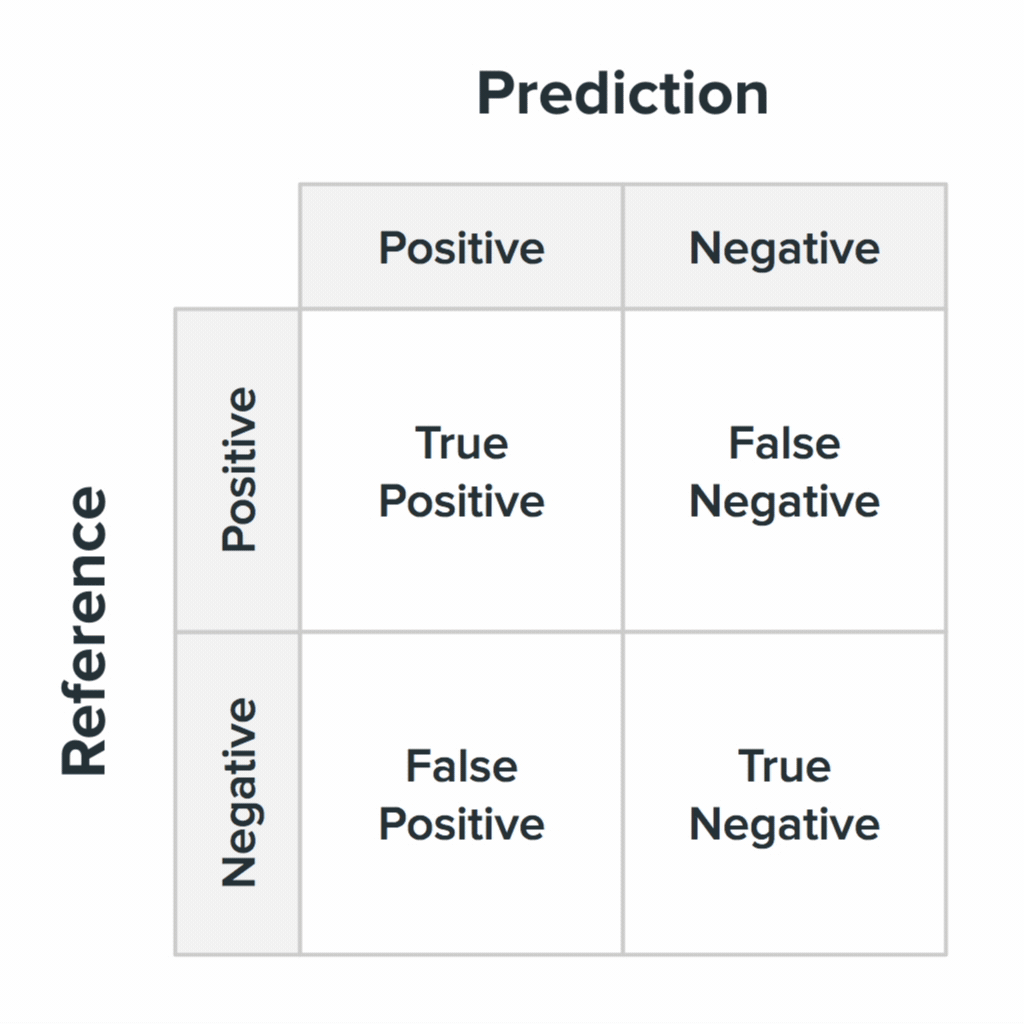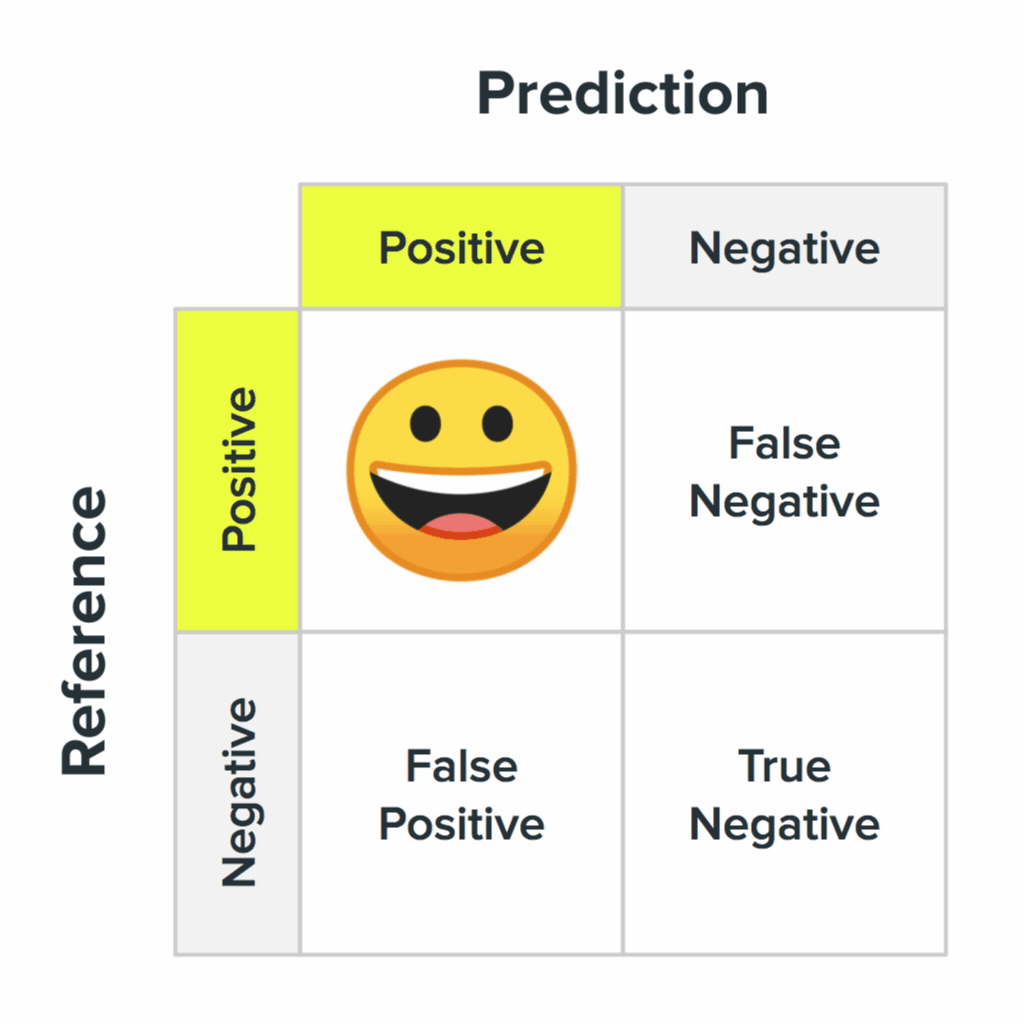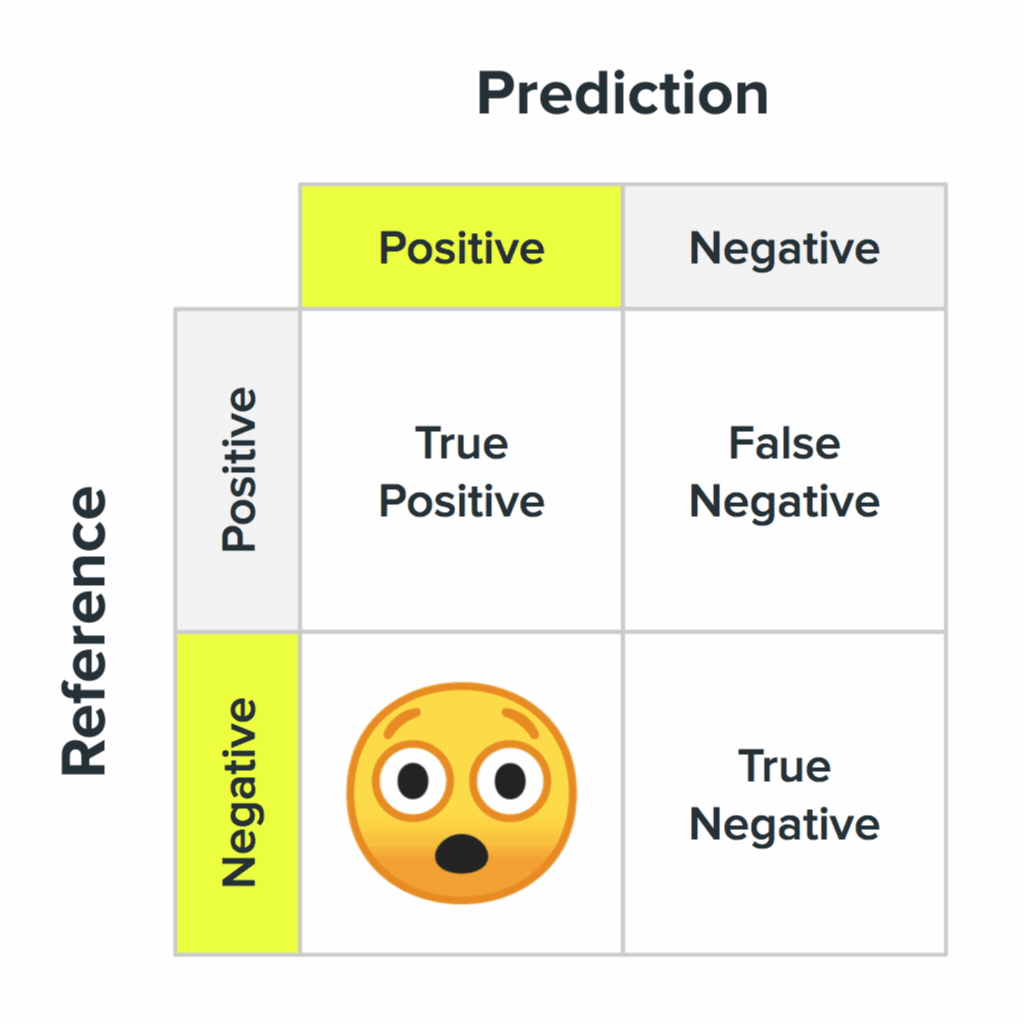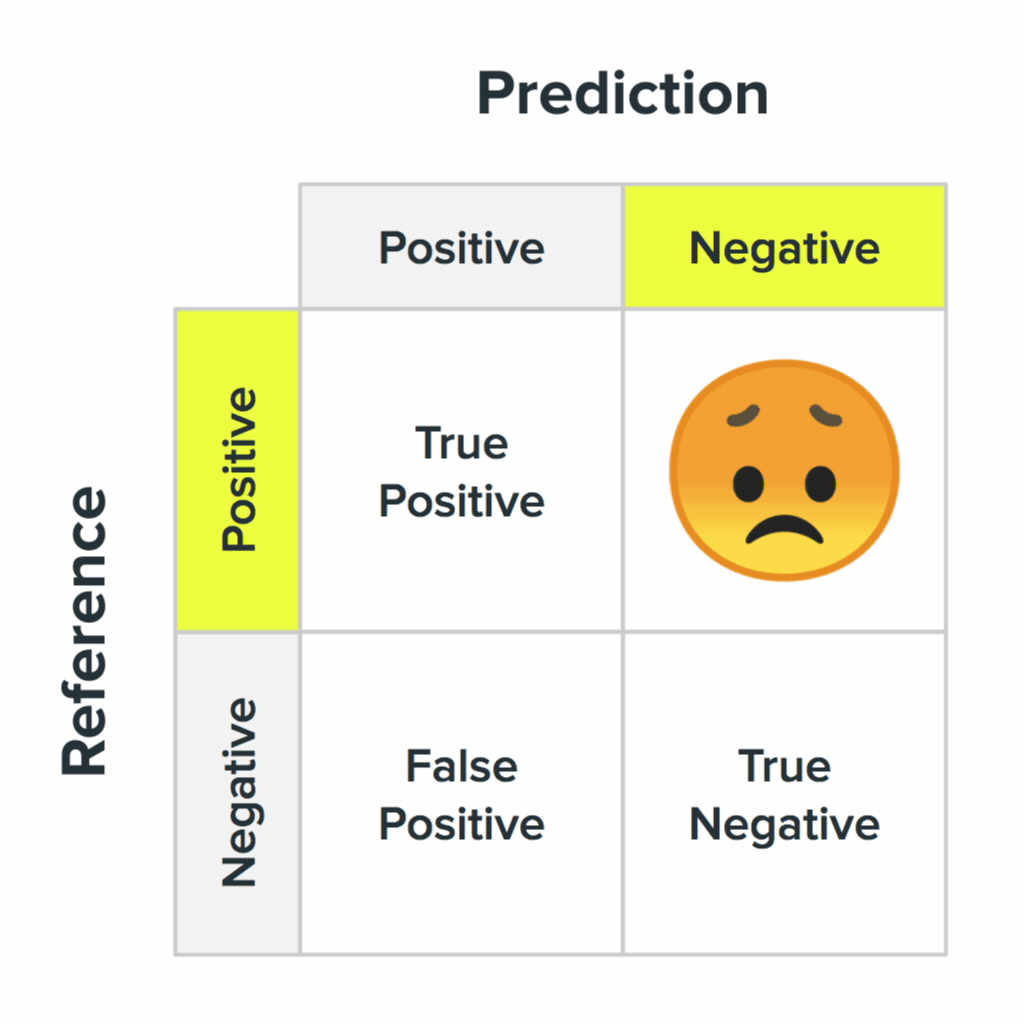
The four states of a confusion matrix and what they likely mean for your users. Image Credit: Akiko Okazaki
While all errors are equal to an ML system, not all errors are equal to all people. For example, if we had a “is this a human or a troll?” classifier, then accidentally classifying a human as a troll is just an error to the system. It has no notion of insulting a user or the cultural context surrounding the classifications it is making. It doesn’t understand that people using the system may be much more offended being accidentally labeled a troll compared to trolls accidentally being labeled as people. But maybe that’s our people-centric bias coming out.

In ML terms, you’ll need to make conscious trade-offs between the precision and recall of the system. That is, you need to decide if it is more important to include all of the right answers even if it means letting in more wrong ones (optimizing for recall), or minimizing the number of wrong answers at the cost of leaving out some of the right ones (optimizing for precision). For example, if you are searching Google Photos for “playground”, you might see results like this:
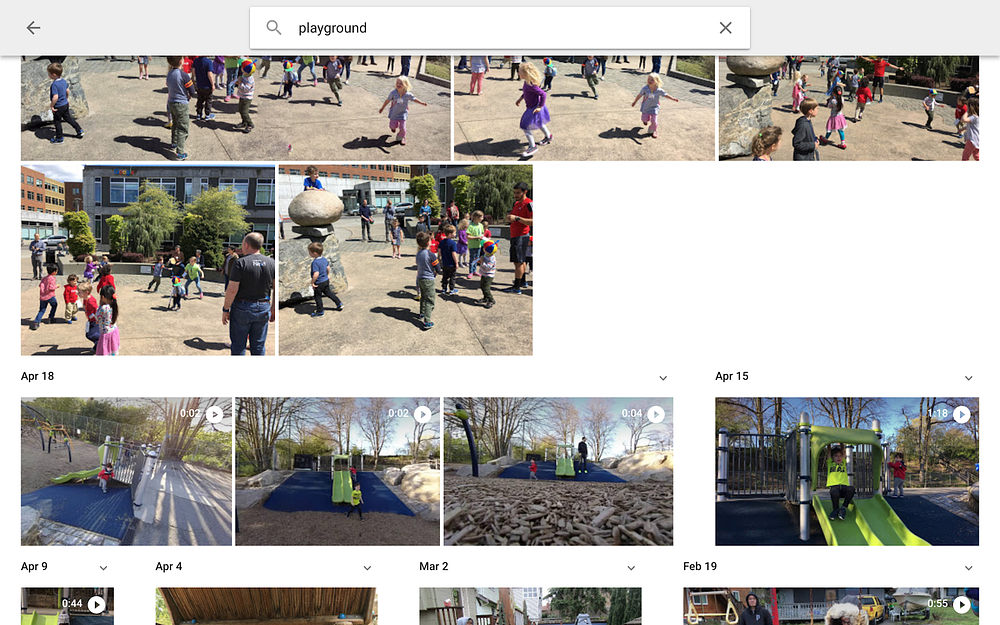
These results include a few scenes of children playing, but not on a playground. In this case, recall is taking priority over precision. It is more important to get all of the playground photos and include a few that are similar but not exactly right than it is to only include playground photos and potentially exclude the photo you were looking for.
5. Plan for co-learning and adaptation
The most valuable ML systems evolve over time in tandem with users’ mental models. When people interact with these systems, they’re influencing and adjusting the kinds of outputs they’ll see in the future. Those adjustments in turn will change how users interact with the system, which will change the models… and so on, in a feedback loop.
This can result in “conspiracy theories” where people form incorrect or incomplete mental models of a system and run into problems trying to manipulate the outputs according to these imaginary rules. You want to guide users with clear mental models that encourage them to give feedback that is mutually beneficial to them and the model.
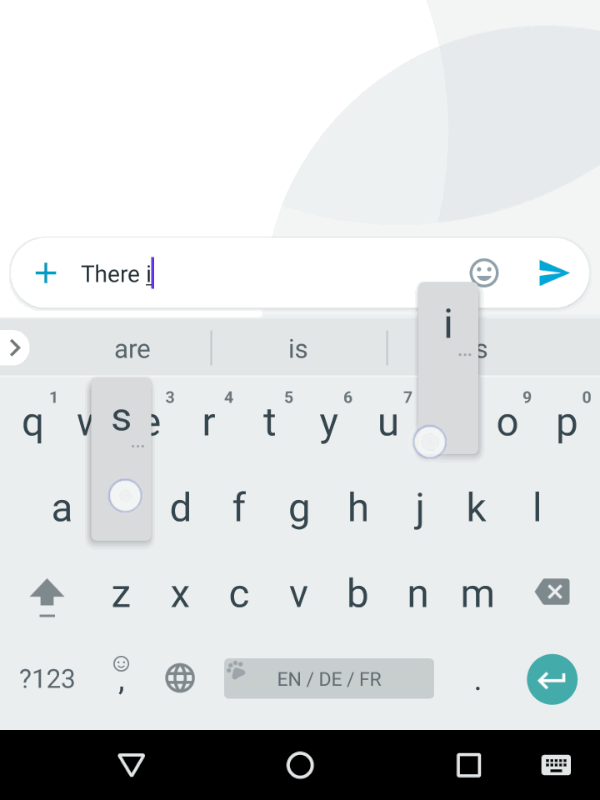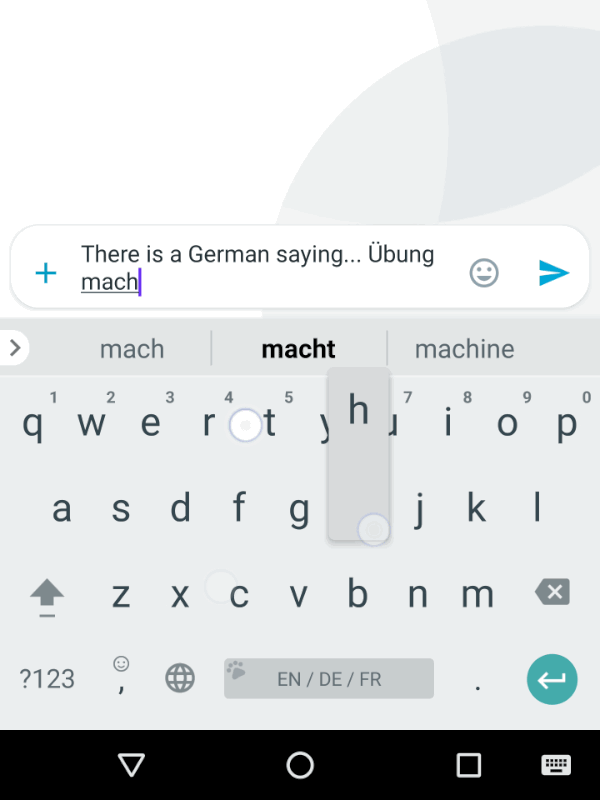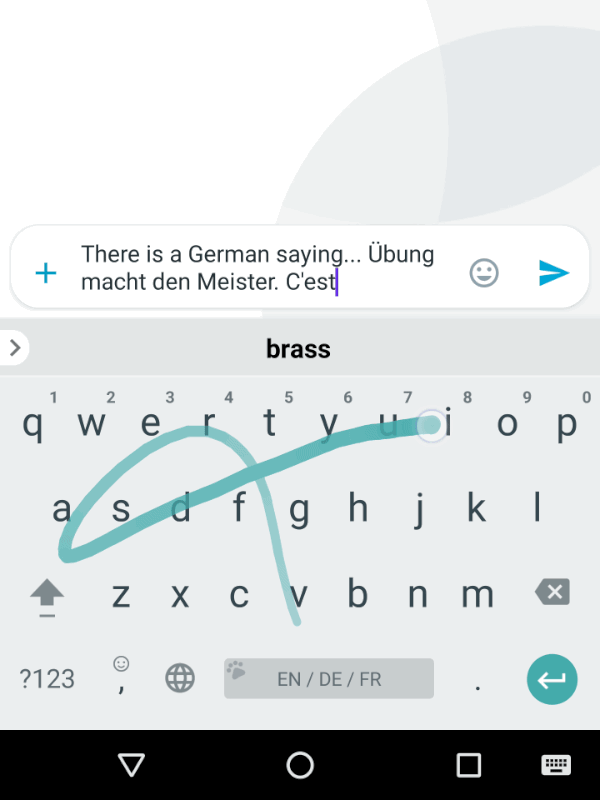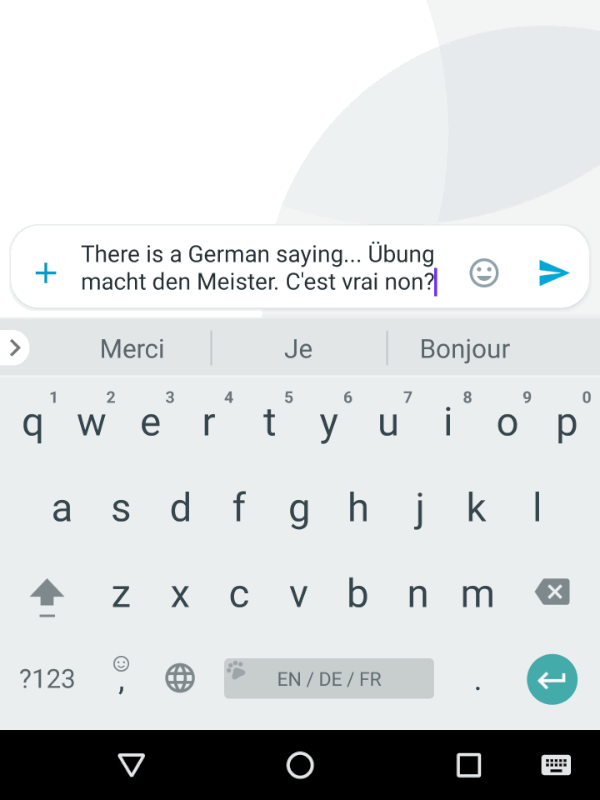
An example of the virtuous cycle is how Gboard continuously evolves to predict the user’s next word. The more someone uses the system’s recommendations, the better those recommendations get. Image Courtesy.
While ML systems are trained on existing data sets, they will adapt with new inputs in ways we often can’t predict before they happen. So we need to adapt our user research and feedback strategies accordingly. This means planning ahead in the product cycle for longitudinal, high-touch, as well as broad-reach research together.
You’ll need to plan enough time to evaluate the performance of ML systems through quantitative measures of accuracy and errors as users and Applications increase, as well as sit with people while they use these systems to understand how mental models evolve with every success and failure.
Additionally, as UXers we need to think about how we can get in situ feedback from users over the entire product lifecycle to improve the ML systems. Designing interaction patterns that make giving feedback easy as well as showing the benefits of that feedback quickly, will start to differentiate good ML systems from great ones.
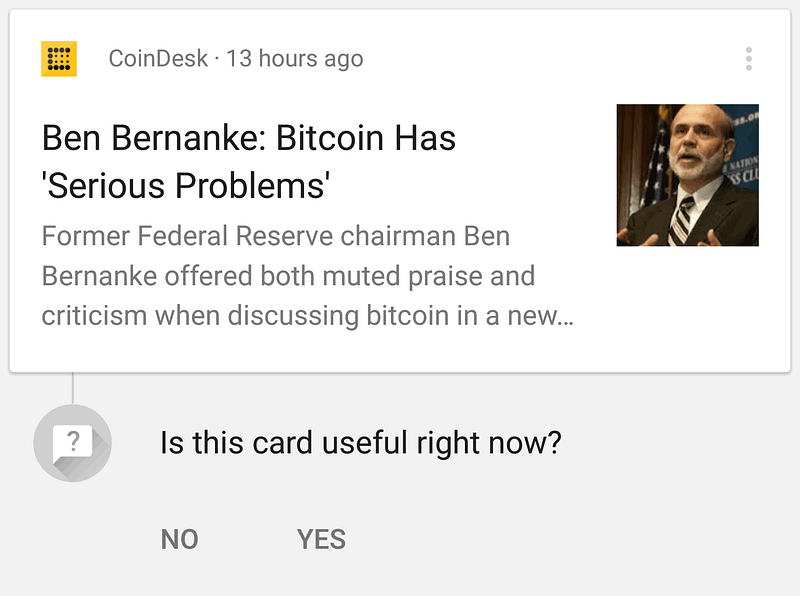
The Google app asks every once in awhile if a particular card is useful right now to get feedback on its suggestions. Image Credit: Google
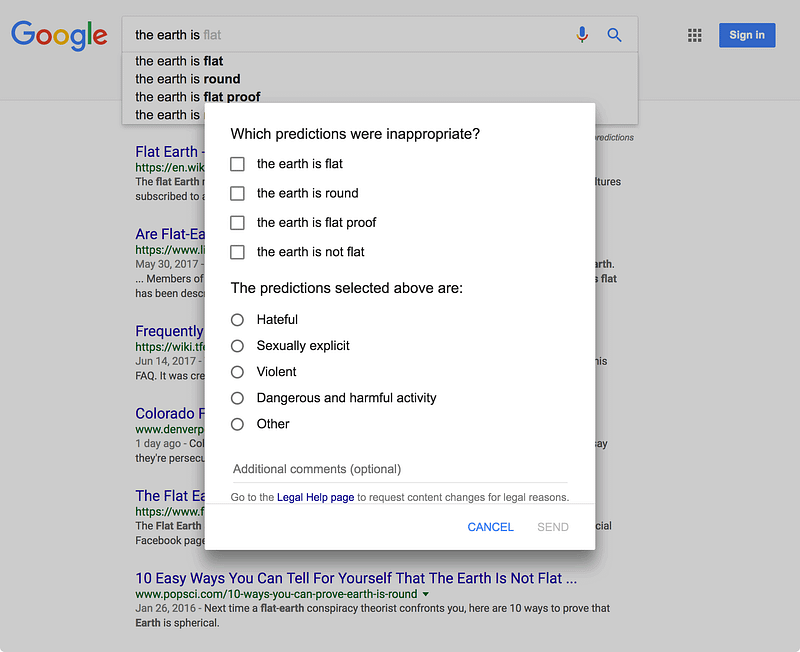
People can give feedback on Google Search Autocomplete including why predictions may be inappropriate. Image Credit: Google
6. Teach your algorithm using the right labels
As UXers, we’ve grown accustomed to wireframes, mockups, prototypes, and redlines being our hallmark deliverables. Well, curveball: when it comes to ML-augmented UX, there’s only so much we can specify. That’s where “labels” come in.
Labels are an essential aspect of machine learning. There are people whose job is to look at tons of content and label it, answering questions like “is there a cat in this photo?” And once enough photos have been labeled as “cat” or “not cat”, you’ve got a data set you can use to train a model to be able to recognize cats. Or more accurately, to be able to predict with some confidence level whether or not there’s a cat in a photo it’s never seen before. Simple, right?

Can you pass this quiz? Image Credit: Google
The challenge comes when you venture into territory where the goal of your model is to predict something that might feel subjective to your users, like whether or not they’ll find an article interesting or a suggested email reply meaningful. But models take a long time to train, and getting a data set fully labeled can be prohibitively expensive, not to mention that getting your labels wrong can have a huge impact on your product’s viability.
So here’s how to proceed: Start by making reasonable assumptions and discussing those assumptions with a diverse array of collaborators. These assumptions should generally take the form of “for ________ users in ________ situations, we assume they’ll prefer ________ and not ________.” Then get these assumptions into the hackiest prototype possible as quickly as possible in order to start gathering feedback and iterating.
Find experts who can be the best possible teachers for your machine learner — people with domain expertise relevant to whatever predictions you’re trying to make. We recommend that you actually hire a handful of them, or as a fallback, transform someone on your team into the role. We call these folks “Content Specialists” on our team.
By this point, you’ll have identified which assumptions are feeling “truthier” than others. But before you go big and start investing in large-scale data collection and labeling, you’ll want to perform a critical second round of validation using examples that have been curated from real user data by Content Specialists. Your users should be testing out a high-fidelity prototype and perceive that they’re interacting with a legit AI (per point #3 above).
With validation in-hand, have your Content Specialists create a broad portfolio of hand-crafted examples of what you want your AI to produce. These examples give you a roadmap for data collection, a strong set of labels to start training models, and a framework for designing large scale labeling protocols.
7. Extend your UX family, ML is a creative process
Think about the worst micro-management “feedback” you’ve ever received as a UXer. Can you picture the person leaning over your shoulder and nit-picking your every move? OK, now keep that image in your mind… and make absolutely certain that you don’t come across like that to your engineers.
There are so many potential ways to approach any ML challenge, so as a UXer, getting too prescriptive too quickly may result in unintentionally anchoring — and thereby diminishing the creativity of — your engineering counterparts. Trust them to use their intuition and encourage them to experiment, even if they might be hesitant to test with users before a full evaluation framework is in place.
Machine learning is a much more creative and expressive engineering process than we’re generally accustomed to. Training a model can be slow-going, and the tools for visualization aren’t great yet, so engineers end up needing to use their imaginations frequently when tuning an algorithm (there’s even a methodology called “Active Learning” where they manually “tune” the model after every iteration). Your job is to help them make great user-centered choices all along the way.
So inspire them with examples — decks, personal stories, vision videos, prototypes, clips from user research, the works — of what an amazing experience could look and feel like, build up their fluency in user research goals and findings, and gently introduce them to our wonderful world of UX crits, workshops, and design sprints to help manifest a deeper understanding of your product principles and experience goals. The earlier they get comfortable with iteration, the better it will be for the robustness of your ML pipeline, and for your ability to effectively influence the product.
Conclusion
These are the seven points we emphasize with teams in Google. We hope they are useful to you as you think through your own ML-powered product questions. As ML starts to power more and more products and experiences, let’s step up to our responsibility to stay human-centered, find the unique value for people, and make every experience great.
Authors
Josh Lovejoy is a UX Designer in the Research and Machine Intelligence group at Google. He works at the intersection of Interaction Design, Machine Learning, and unconscious bias awareness, leading design and strategy for Google’s ML Fairness efforts.
Jess Holbrook is a UX Manager and UX Researcher in the Research and Machine Intelligence group at Google. He and his team work on multiple products powered by AI and machine learning that take a human-centered approach to these technologies.
Akiko Okazaki did the beautiful illustrations.
The Most Comprehensive IoT Newsletter for Enterprises
Showcasing the highest-quality content, resources, news, and insights from the world of the Internet of Things. Subscribe to remain informed and up-to-date.
New Podcast Episode

IoT Is Finally Delivering
Related Articles


Related Solutions

Smart License Plate Recognition
Automate parking enforcement and access control with real-time vehicle identification to improves revenue collection.
Automate parking enforcement and access control with real-time vehicle identification to improves revenue collection.
Conure
Conure

Retail Shelf Utilization Monitoring
Improve inventory management, boost revenue, optimize staff efficiency, and enhance customer experience.
Improve inventory management, boost revenue, optimize staff efficiency, and enhance customer experience.
Leverege
Leverege

Bottom of Basket for Grocery Stores
Enables grocery stores to automatically detect bottom cart items, alert cashiers and help reduce shrinkage
Enables grocery stores to automatically detect bottom cart items, alert cashiers and help reduce shrinkage
Leverege
Leverege
Related Solutions
Smart Cities
Smart License Plate Recognition
Automate parking enforcement and access control with real-time vehicle identification to improves revenue collection.
Conure
Retail
Retail Shelf Utilization Monitoring
Improve inventory management, boost revenue, optimize staff efficiency, and enhance customer experience.
Leverege
Retail
Bottom of Basket for Grocery Stores
Enables grocery stores to automatically detect bottom cart items, alert cashiers and help reduce shrinkage
Leverege