TinyML That Can Be Updated Without Resynthesizing or Rebooting the FPGA
TinyML That Can Be Updated Without Resynthesizing or Rebooting the FPGA
- Last Updated: December 2, 2024
Microchip Technology
- Last Updated: December 2, 2024

Provide a Simple and Future-Proof Approach to Incorporating ML in a Variety of Systems
FPGA chips are projected to dominate IoT endpoint Deep Neural Nets (DNN) by the end of this decade [1]. They are more energy-efficient and faster than microcontrollers, and easier to develop than ASICs. Infxl has teamed up with Microchip to speed up their adoption by offering two technological advantages:
1. Simple tools for going from training data to a compact DNN in C to HLS
2. TinyML FPGA implementation that can be updated without requiring a resynthesis or reboot
The first of these addresses a common concern of the embedded developer community: the ML and FPGA tools require a level of expertise that is costly and difficult to find.
The second one addresses an inherent issue to Machine Learning (ML): ML solutions become stale after a while and require periodic rejuvenation. We present a DNN-on-FPGA design that ensures that DNNs can be updated without resynthesizing, reimplementing, or rebooting the FPGA.
The energy efficiency and speed advantage of FPGA implementations can be further magnified by using ML models that are simple and compact. Infxl net is one such model (example code [2]). It implements a fully connected DNN in simple C using 8/16-bit data paths without multiplications or floating-point operations.
A vital feature of the Infxl net is the clear separation it maintains between the network structure/parameters and the inference engine. We exploit this feature by keeping the parameters in LSRAM while implementing the engine with LUTs and FFs. We update the parameters in LSRAM, and the FPGA almost immediately starts delivering improved results based on the updated network structure/parameters. This way, when we need to update a deployed Infxl net, we do not need to resynthesize, reimplement, or even reboot the FPGA.
Microchip and Infxl have teamed up to provide a simple and future-proof approach to incorporating Machine Learning in a variety of systems.
Development Process
The development process consists of two main steps:
• Upload preprocessed data to cloud.infxl.com and download the trained Infxl net as ready-to-use C code. This process does not require any background in ML.
• Use Microchip's easy-to-use SmartHLS compiler [3] to generate HLS from C code according to the project's exact requirements. SmartHLS is an Eclipse-based IDE that takes C/C++ code as input and generates a SmartDesign IP component (Verilog HDL) as output. To build an FPGA system, we can instantiate the generated SmartDesign IP component in the SmartDesign canvas available in the Libero SoC design suite [4].
The Infxl net C code includes a testbench and a generic interface. A few simple modifications are needed before it can be deployed in an FPGA:
• Define the preferred interconnect, e.g., register or AXI4 interface for the incoming sensor data.
• Define the mechanism for communicating the class predicted by the Infxl net.
• Change the memory type for the Infxl net to simulation-only and define a memory external to the C code but still inside the FPGA.
• Create a top-level function in the C code to incorporate the Infxl net. This will be the IP instantiated into the overall FPGA system afterward.
The default Infxl net C code interfaces the inference engine to inputs and outputs through a small amount of RAM. This is a typical approach for microcontrollers. For an FPGA implementation, it is more efficient to interact with a FIFO-like interface. Additional small functions were added to the default Infxl net C code to accommodate this. The code for the Infxl net's inference engine, however, remained untouched.
See below for a comparison of the original and the modified C code.
Original:
<!-- wp:paragraph --> <p>Modified:<img src=" />
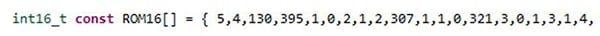
Modified:
<!-- wp:paragraph --> <p>In the testbench, ROM16 will be populated before the Infxl net is run. The equivalent loading is required in the full FPGA design as well. This loading mechanism also enables the updating of already deployed Infxl nets:<img src=" />predictive maintenance to environmental monitoring to robotics to malware detection to healthcare wearables, and many more.
Notes:
[1] TinyML: The Next Big Opportunity in Tech (Published May 2021 by ABI Research https://www.abiresearch.com/market-research/product/7779411-tinyml-the-next-big-opportunity-in-tech/)
[2] https://cloud.infxl.com/infxltrainednetfpga
[3] https://www.microsemi.com/product-directory/fpga-design-tools/5590-hls
[4] https://www.microsemi.com/product-directory/design-resources/1750-libero-soc
The Most Comprehensive IoT Newsletter for Enterprises
Showcasing the highest-quality content, resources, news, and insights from the world of the Internet of Things. Subscribe to remain informed and up-to-date.
New Podcast Episode

IoT Is Finally Delivering
Related Articles


Related Solutions

Smart License Plate Recognition
Automate parking enforcement and access control with real-time vehicle identification to improves revenue collection.
Automate parking enforcement and access control with real-time vehicle identification to improves revenue collection.
Conure
Conure

Retail Shelf Utilization Monitoring
Improve inventory management, boost revenue, optimize staff efficiency, and enhance customer experience.
Improve inventory management, boost revenue, optimize staff efficiency, and enhance customer experience.
Leverege
Leverege

Bottom of Basket for Grocery Stores
Enables grocery stores to automatically detect bottom cart items, alert cashiers and help reduce shrinkage
Enables grocery stores to automatically detect bottom cart items, alert cashiers and help reduce shrinkage
Leverege
Leverege
Related Solutions
Smart Cities
Smart License Plate Recognition
Automate parking enforcement and access control with real-time vehicle identification to improves revenue collection.
Conure
Retail
Retail Shelf Utilization Monitoring
Improve inventory management, boost revenue, optimize staff efficiency, and enhance customer experience.
Leverege
Retail
Bottom of Basket for Grocery Stores
Enables grocery stores to automatically detect bottom cart items, alert cashiers and help reduce shrinkage
Leverege