Machine Learning Trends To Impact Business In 2021-2022
Machine Learning Trends To Impact Business In 2021-2022
- Last Updated: December 2, 2024
MobiDev
- Last Updated: December 2, 2024

Like many other revolutionary technologies of the modern day, machine learning was once science fiction. However, its applications in real world industries are only limited by our imagination. In 2021, recent innovations in machine learning have made a great deal of tasks more feasible, efficient, and precise than ever before.
Powered by data science, machine learning makes our lives easier. When properly trained, they can complete tasks more efficiently than a human.
Understanding the possibilities and recent innovations of ML technology is important for businesses so that they can plot a course for the most efficient ways of conducting their business. It is also important to stay up to date to maintain competitiveness in the industry.
Machine learning models have come a long way before being adopted into production.
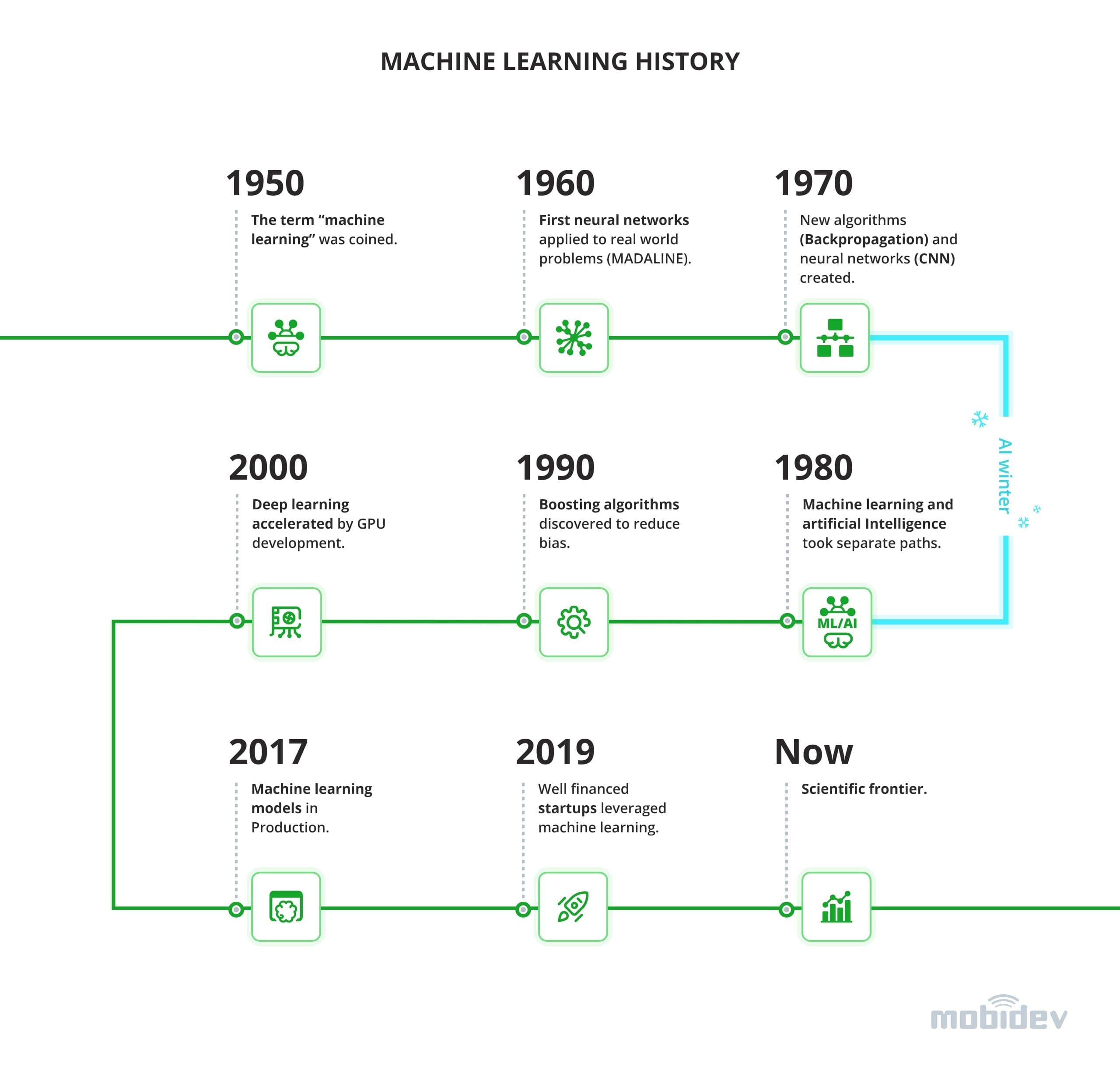
In this article, we will discuss the latest innovations in machine learning technology in 2021 with various examples of how this technology can benefit you and your business.
Trend #1: No-Code Machine Learning
Although much of machine learning is handled and set up using computer code, this is no longer always the case. No-code machine learning is a way of programming ML applications without having to go through the long and arduous processes of pre-processing, modeling, designing algorithms, collecting new data, retraining, deployment, and more. Some of the main advantages are:
Quick implementation. Without any code needed to be written or the need for debugging, most of the time spent will be on getting results instead of development.
Lower costs. Since automation eliminates the need for longer development time, large data science teams are no longer necessary.
Simplicity: No-code ML is easier to use due to its simplistic drag and drop format.
No-code machine learning uses drag and drop inputs to simplify the process into the following:
- Begin with user behavior data
- Drag and drop training data
- Use a question in plain English
- Evaluate the results
- Generate a prediction report
Since this greatly simplifies the machine learning process, taking the time to become an expert is not necessary. Although this makes machine learning applications more accessible to developers, it is not a substitute for more advanced and nuanced projects.
However, it may be suitable for simple data analysis predictive projects like retail profits, dynamic pricing, and employee retention rates.
No-code algorithms are the best choice for smaller companies that cannot afford to maintain a team of data scientists. Although its use cases are limited, no-code ML is a great choice for analyzing data and making predictions over time without a great deal of development or expertise.
Trend #2: TinyML
In a world increasingly driven by IoT solutions, TinyML makes its way into the mix. While large scale machine learning applications exist, their usability is fairly limited. Smaller scale applications are often necessary. It can take time for a web request to send data to a large server for it to be processed by a machine learning algorithm and then sent back. Instead, a more desirable approach might be to use ML programs on edge devices.
With data science and machine learning, industries are becoming more advanced by the day, making the technology necessary to remain competitive.
By running smaller scale ML programs on IoT edge devices, we can achieve lower latency, lower power consumption, lower required bandwidth, and ensure user privacy. Since the data doesn’t need to be sent out to a data processing center, latency, bandwidth, and power consumption are greatly reduced. Privacy is also maintained since the computations are made entirely locally.
This trending innovation has a great deal of applications in sectors like predictive maintenance for industrial centers, healthcare industries, agriculture, and more. These industries utilize IoT devices with TinyML algorithms to track and make predictions on collected data. For example, Solar Scare Mosquito is an IoT project which uses TinyML to measure the presence of mosquitos in real time. This can generate early warning systems for disease epidemics from mosquitos, for example.
Trend #3: AutoML
Similar in objective to no-code ML, AutoML aims to make building machine learning applications more accessible for developers. Since machine learning has become increasingly more useful in various industries, off-the-shelf solutions have been in high demand. Auto-ML aims to bridge the gap by providing an accessible and simple solution that does not rely on the ML-experts.
Data scientists working on machine learning projects have to focus on preprocessing the data, developing features, modeling, designing neural networks if deep learning is involved in the project, post processing, and result analysis. Since these tasks are very complex, AutoML provides simplification through use of templates.
An example of this is AutoGluon, an off-the-shelf solution for text, image, and tabular data. This allows developers to quickly prototype deep learning solutions and get predictions without the need of data science experts.
AutoML brings improved data labeling tools to the table and enables the possibility of automatic tuning of neural network architectures. Traditionally, data labeling has been done manually by outsourced labor. This brings in a great deal of risk due to human error. Since AutoML aptly automates much of the labeling process, the risk of human error is much lower. This also reduces labor costs, allowing companies to focus much more strongly on data analysis. Since AutoML reduces these kinds of costs, data analysis, artificial intelligence, and other solutions will become cheaper and more accessible to companies in the market.
Another example of AutoML in action is OpenAI’s DALL-E and CLIP (contrastive language image pre-training) models. These two models combine text and images to create new visual designs from a text-based description. One of the early examples of this in action is how the models can be used to generate images based on the input description “armchair in the shape of an avocado.” This technology has many interesting applications, such as the creation of original images for article SEO, creating mockups of new products, and quickly generating product ideas.
Trend #4: Machine Learning Operationalization Management (MLOps)
Machine Learning Operationalization Management (MLOps) is a practice of developing machine learning software solutions with a focus on reliability and efficiency. This is a novel way of improving the way that machine learning solutions are developed to make them more useful for businesses.
Machine learning and AI can be developed with traditional development disciplines, but the unique traits of this technology mean that it may be better suited for a different strategy. MLOps provides a new formula that combines ML systems development and ML systems deployment into a single consistent method.
One of the reasons why MLOps is necessary is that we are dealing with more and more data on larger scales which requires greater degrees of automation. One of the major elements of MLOps is the systems life cycle, introduced by the DevOps discipline.
Understanding the ML systems lifecycle is essential for understanding the importance of MLOps.
- Design a model based on business goals
- Acquire, process and prepare data for the ML model
- Train and tune ML model
- Validate ML model
- Deploy the software solution with integrated model
- Monitor and restart process to improve ML model
One of the advantages of MLOps is that it can easily address systems of scale. It’s difficult to deal with these problems at larger scales because of small data science teams, gaps in internal communication between teams, changing objectives, and more.
When we utilize business objective-first design, we can better collect data and implement ML solutions throughout the entire process. These solutions need to pay close attention to data relevancy, feature creation, cleaning, finding appropriate cloud service hosts, and ease of model training after deployment to a production environment.
By reducing variability and ensuring consistency and reliability, MLOps can be a great solution for enterprises at scale.
Kubernetes is a DevOps tool that has proved to be efficient for allocating hardware resources for AI/ML workloads, namely, memory, CPU, GPU, and storage. Kubernetes implements auto-scaling and provides real-time computing resources optimization.
Trend #5: Full-stack Deep Learning
Wide spreading of deep learning frameworks and business needs to be able to include deep learning solutions into products led to the emergence of a large demand for “full-stack deep learning”.
What is full-stack deep learning? Let’s imagine you have highly qualified deep learning engineers that have already created some fancy deep learning model for you. But right after the creation of the deep learning model it is just a few files that are not connected to the outer world where your users live.
As the next step, engineers have to wrap the deep learning model into some infrastructure:
- Backend on a cloud
- Mobile application
- Some edge devices (Raspberry Pi, NVIDIA Jetson Nano, etc.)
The demand of full-stack deep learning results in the creation of libraries and frameworks that help engineers to automate some shipment tasks (like the chitra project does) and education courses that help engineers to quickly adapt to new business needs (like open source fullstackdeeplearning projects).
Trend #6: General Adversarial Networks (GAN)
GAN technology is a way of producing stronger solutions for implementations such as differentiating between different kinds of images. Generative neural networks produce samples that must be checked by discriminative networks which toss out unwanted generated content. Similar to branches of government, General Adversarial Networks offer checks and balances to the process and increase accuracy and reliability.
It’s important to remember that a discriminative model cannot describe categories that it is given. It can only use conditional probability to differentiate samples between two or more categories. Generative models focus on what these categories are and distribute joint probability.
A useful application of this technology is for identifying groups of images. With this in mind, large scale tasks such as image removal, similar image search, and more are possible. Another important application of GANs is image generation task.
Trend #7: Unsupervised ML
As automation improves, more and more data science solutions are needed without human intervention. Unsupervised ML is a trend that shows promise for various industries and use cases. We already know from previous techniques that machines cannot learn in a vacuum. They must be able to take new information and analyze that data for the solution that they provide. However, this typically requires human data scientists to feed that information into the system.
Unsupervised ML focuses on unlabeled data. Without guidance from a data scientist, unsupervised machine learning programs have to draw their own conclusions. This can be used to quickly study data structures to identify potentially useful patterns and use this information to improve and further automate decision-making.
One technique that can be used to investigate data is clustering. By grouping data points with shared features, machine learning programs can understand data sets and their patterns more efficiently.
Trend #8: Reinforcement Learning
In machine learning, there are three paradigms: supervised learning, unsupervised learning, and reinforcement learning. In reinforcement learning, the machine learning system learns from direct experiences with its environment. The environment can use a reward/punishment system to assign value to the observations that the ML system sees. Ultimately, the system will want to achieve the highest level of reward or value, similar to positive reinforcement training for animals.
This has a great deal of application in video game and board game AI. However, when safety is a critical feature of the application, reinforcement ML may not be the best idea. Since the algorithm comes to conclusions with random actions, it may deliberately make unsafe decisions in the process of learning. This can endanger users if left unchecked. There are safer reinforcement learning systems in development to help with this issue that take safety into account for their algorithms.
Once reinforcement learning can complete tasks in the real world without choosing dangerous or harmful actions, RL will be a much more helpful tool in a data scientist’s arsenal.
Trend #9: Few Shot, One Shot, & Zero Shot Learning
Data collection is essential for machine learning practices. However, it is also one of the most tedious tasks and can be subject to error if done incorrectly. The performance of the machine learning algorithm heavily depends on the quality and type of data that is provided. A model trained to recognize various breeds of domestic dogs would need new classifier training to recognize and categorize wild wolves.
Few shot learning focuses on limited data. While this has limitations, it does have various applications in fields like image classification, facial recognition, and text classification. Although not requiring a great deal of data to produce a usable model is helpful, it cannot be used for extremely complex solutions.
Likewise, one shot learning uses even less data. However, it has some useful applications for facial recognition. For example, one could compare a provided passport ID photo to the image of a person through a camera. This only requires data that is already present and does not need a large database of information.
Zero shot learning is an initially confusing prospect. How can machine learning algorithms function without initial data? Zero shot ML systems observe a subject and use information about that object to predict what classification they may fall into. This is possible for humans. For example, a human who had never seen a tiger before but had seen a housecat would probably be able to identify the tiger as some kind of feline animal.
Although the observed objects are not seen during training, the ML algorithm can still classify observed objects into categories. This is very useful for image classification, object detection, natural language processing and other tasks.
A remarkable example of a few-shot learning application is drug discovery. In this case, the model is being trained to research new molecules and detect useful ones that can be added in new drugs. New molecules that haven’t gone through clinical trials can be toxic or ineffective, so it’s crucial to train the model using a small number of samples.
Machine Learning: Powering Into the Future
With data science and machine learning, industries are becoming more and more advanced by the day. In some cases, this has made the technology necessary to remain competitive. However, utilizing this technology on its own can only get us so far. We need to innovate to achieve goals in novel and unique ways to truly stake a corner in the market and break into new futures that previously were thought to be science fiction.
Every objective requires different methods to achieve. Talking to experts about what’s best for your company can help you understand what technologies, such as machine learning, can improve the efficiency of your business and help you achieve your vision of supporting your clients.
The Most Comprehensive IoT Newsletter for Enterprises
Showcasing the highest-quality content, resources, news, and insights from the world of the Internet of Things. Subscribe to remain informed and up-to-date.
New Podcast Episode

IoT Is Finally Delivering
Related Articles



Related Solutions

Smart License Plate Recognition
Automate parking enforcement and access control with real-time vehicle identification to improves revenue collection.
Automate parking enforcement and access control with real-time vehicle identification to improves revenue collection.
Conure
Conure

Retail Shelf Utilization Monitoring
Improve inventory management, boost revenue, optimize staff efficiency, and enhance customer experience.
Improve inventory management, boost revenue, optimize staff efficiency, and enhance customer experience.
Leverege
Leverege

Bottom of Basket for Grocery Stores
Enables grocery stores to automatically detect bottom cart items, alert cashiers and help reduce shrinkage
Enables grocery stores to automatically detect bottom cart items, alert cashiers and help reduce shrinkage
Leverege
Leverege
Related Solutions
Smart Cities
Smart License Plate Recognition
Automate parking enforcement and access control with real-time vehicle identification to improves revenue collection.
Conure
Retail
Retail Shelf Utilization Monitoring
Improve inventory management, boost revenue, optimize staff efficiency, and enhance customer experience.
Leverege
Retail
Bottom of Basket for Grocery Stores
Enables grocery stores to automatically detect bottom cart items, alert cashiers and help reduce shrinkage
Leverege